Prefix Cache:前缀 KV Cache 缓存
5 min
本文从 KV Cache 的复用动机出发,介绍 Prefix cache 的优化方法,并进一步分析 vLLM v1 如何将其演化为接近 zero-overhead 的“free lunch”机制。
Prefix Cache (vLLM v0 naive version)
在 LLM 推理中,许多请求往往共享相同的前缀,例如对话系统中的 system prompt 往往对所有请求都是一致的。基于这一观察,系统可以缓存已经计算过的前缀对应的 KV Cache,并在后续具有相同前缀的请求中直接复用。这种 prefix cache 机制带来两个主要好处:
- 避免重复构建相同前缀的 KV Cache,从而降低系统的 KV Cache 内存占用;
- 避免对相同前缀重复执行 prefill 计算,从而减少计算开销并降低请求延迟。
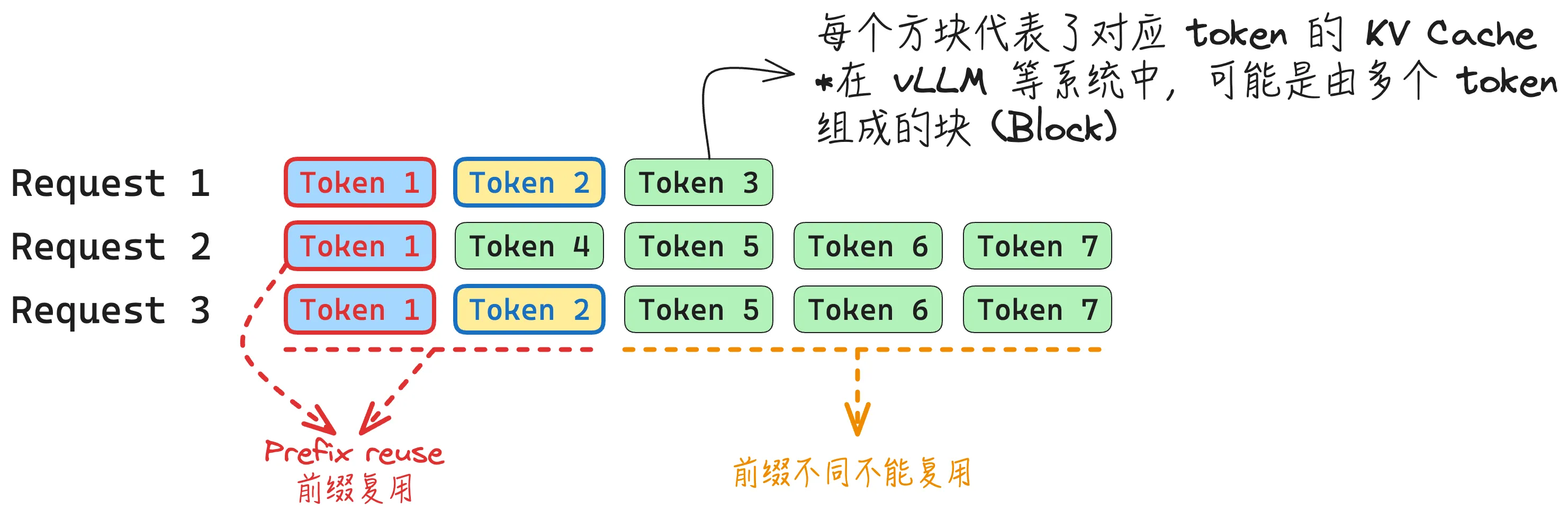
如下图所示,
- Request 2 可以复用 Request 1 的第一个 token 的 KV Cache,
- Request 3 可以服用 Request 1 的第一和第二个 token 的 KV Cache.
- Request 3 的 Token 5-7 不能复用 Request 2 的对应 token 的 KV Cache 是因为两个请求的前缀不同,因此对应的 KV Cache 自然也不同。
为了实现 Prefix cache 机制,我们需要考虑以下几个问题:
- 前缀匹配搜索。对于新请求的 prompt,对于新请求的 prompt,系统需要高效地在已有的历史前缀缓存中查找可匹配的前缀,并定位可以直接复用的 KV Cache blocks。
- Eviction 策略。系统内存资源是有限的,当请求很多的时候,就需要做 eviction 策略来回收不常用的 KV Cache。
- Block 大小与 Cache hit rate. 在 vLLM 系统中,往往一个 KV Cache Block 包含多个 token,此时 block size 就非常重要。较大的 block size 可以降低管理和查找开销,但可能降低缓存命中率;较小的 block size 能提高复用粒度和命中率,但会带来更高的元数据管理和调度开销。
Prefix cache 的收益。Prefix cache 并不总是能带来收益,当 hit rate 很低时,由于存在前缀匹配搜索开销,所以存在一定可能导致收益损失。
vLLM v1 Prefix Cache 实现
下图展示 vLLM v1 KV Cache 管理组件。KV Cache 被组织为固定大小的 Block,作为内存管理的基本单位。系统主要包括以下组件:
- Request Block Table(请求块表):维护每个请求对应的 KV Cache Block 序列(逻辑映射)。由于前缀复用,不同请求之间可以共享同一 Block。
- Prefix Cache Index(前缀缓存索引):基于前缀的哈希,将 prefix 映射到已有的 KV Cache Block,用于快速查找和复用已计算的前缀。
- Block Pool:维护空闲的 KV Cache Blocks(通常通过链表结构),用于高效分配与回收,避免频繁内存分配带来的开销和碎片问题。
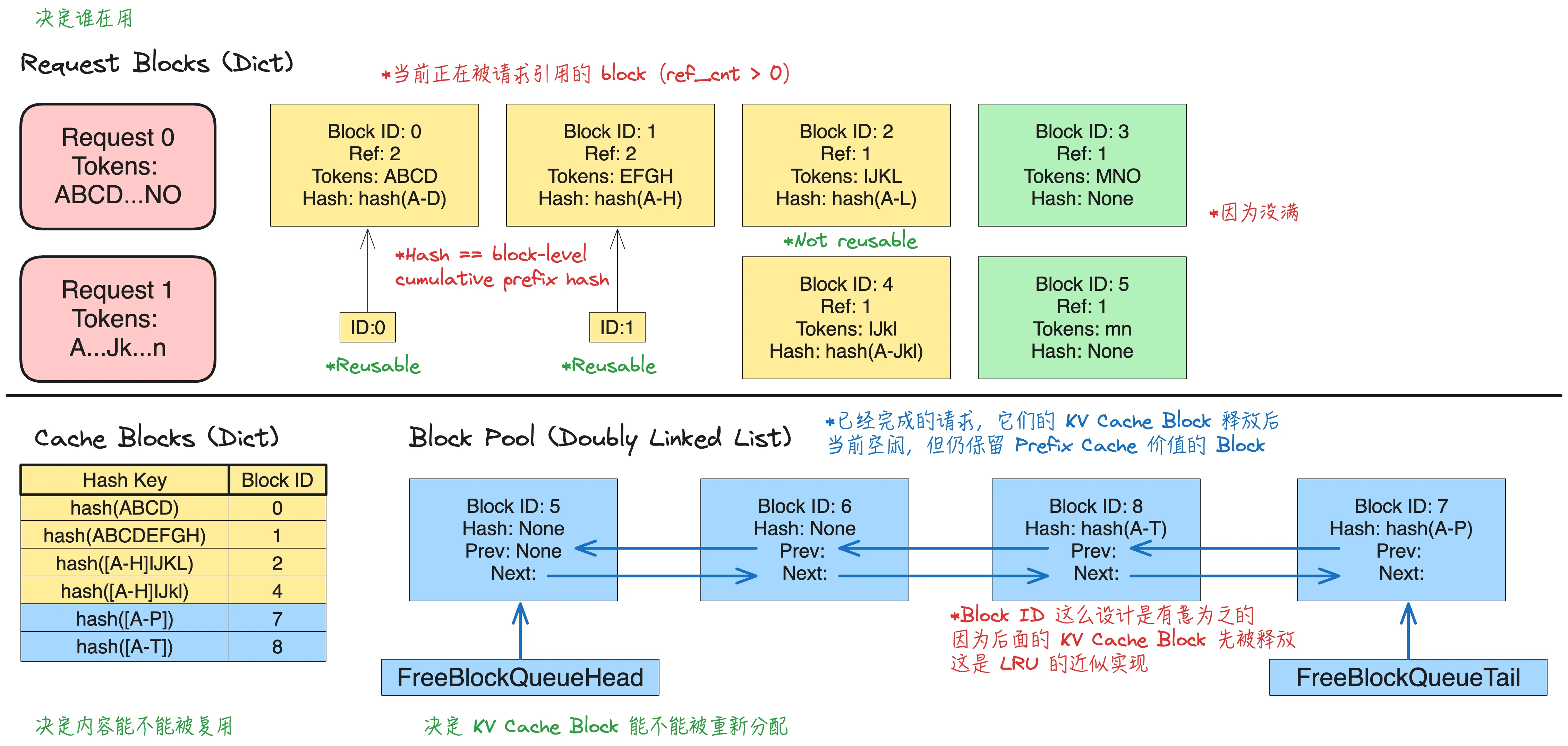
在有新请求进来的时候:
- 系统首先按 block 粒度,根据请求预先计算好的 block hash,在 cache 中按前缀顺序查找可复用的 完整 KV Cache Blocks。一旦某个 block 不命中,就停止继续向后匹配。命中的 block 可能有两种状态:
- ref_cnt > 0:当前正被其他请求使用;
- ref_cnt = 0:当前无请求使用,但仍保留在 cache 中,同时位于 Free Block Queue。
- 这两种 block 都可以直接复用;若命中的是 free queue 中的 block,需要先将其从 free queue 中移除,再增加引用计数。
- 在扣除这些已复用的 block 之后,系统计算该请求还需要新分配多少 block,并检查当前是否有足够可用 block。
- 对于无法复用的后续部分,系统从 Free Block Queue 中取出新的 block 供该请求使用;随着后续计算写入 token,当某个 block 被填满后,才会进一步更新其 hash metadata,并加入 cache,供未来请求复用。