vLLM v1 离线推理流程源码 Debug
我们以 examples/basic/offline_inference/basic.py 为例进行调试,可以看到在用户准备好 prompts: list[str] 与 sampling_params: SamplingParams 之后,整个离线推理流程表面上只分为两个步骤:
- 初始化
LLM - 调用
llm.generate(...)获得输出
看起来非常简单,但实际上这是整一套复杂推理系统的冰山一角。真正的工作——包括进程启动、EngineCore 初始化、模型加载、KV Cache 管理、调度器构建、通信系统建立,以及 GPU execution runtime 的准备——都藏在复杂的多进程多线程系统之后。
在本篇文章里面我们从最简单的离线推理例子 walk through 整套 vLLM 系统的推理流程。
本文参考 vLLM 版本:vllm-260519
vLLM v1 离线推理核心组件示意图
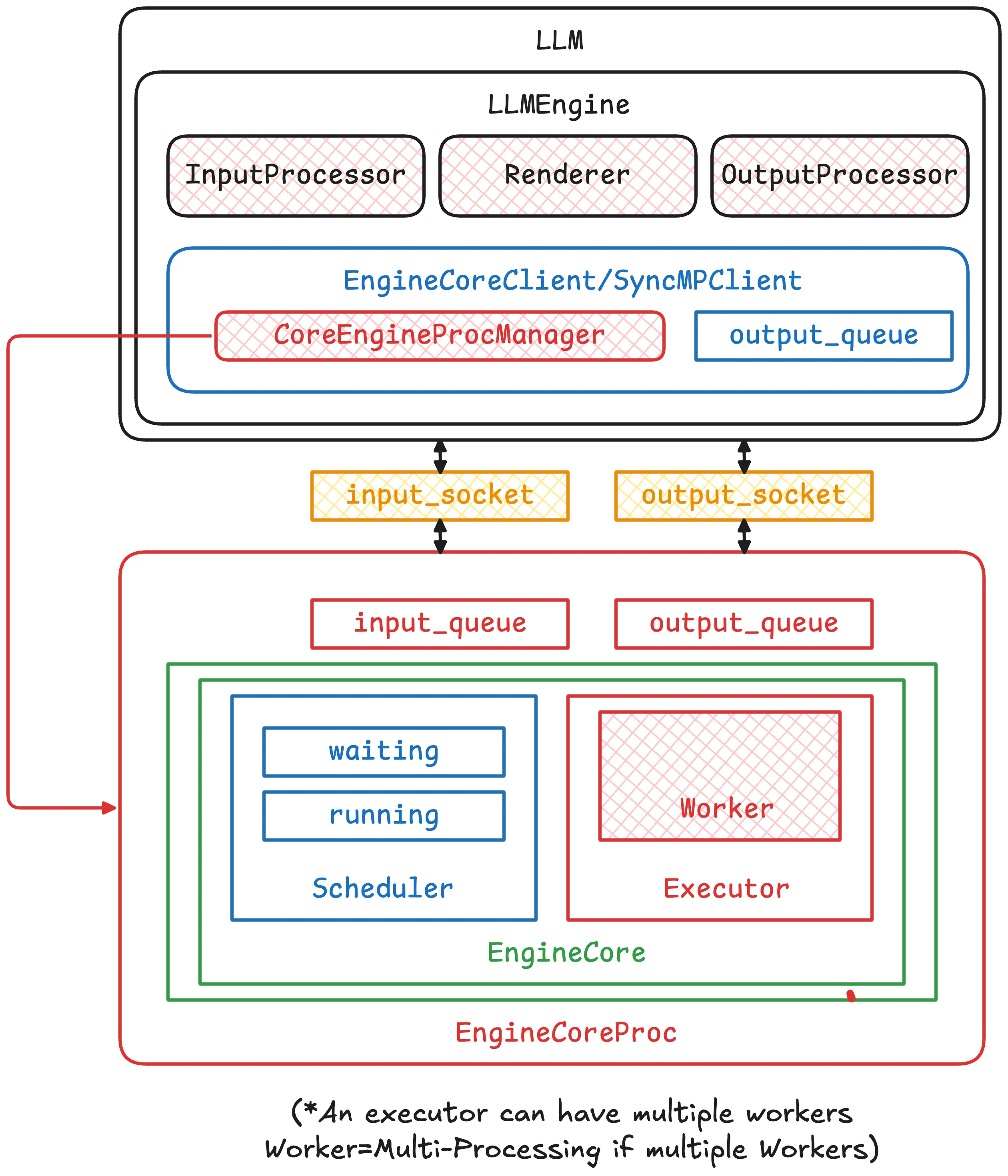
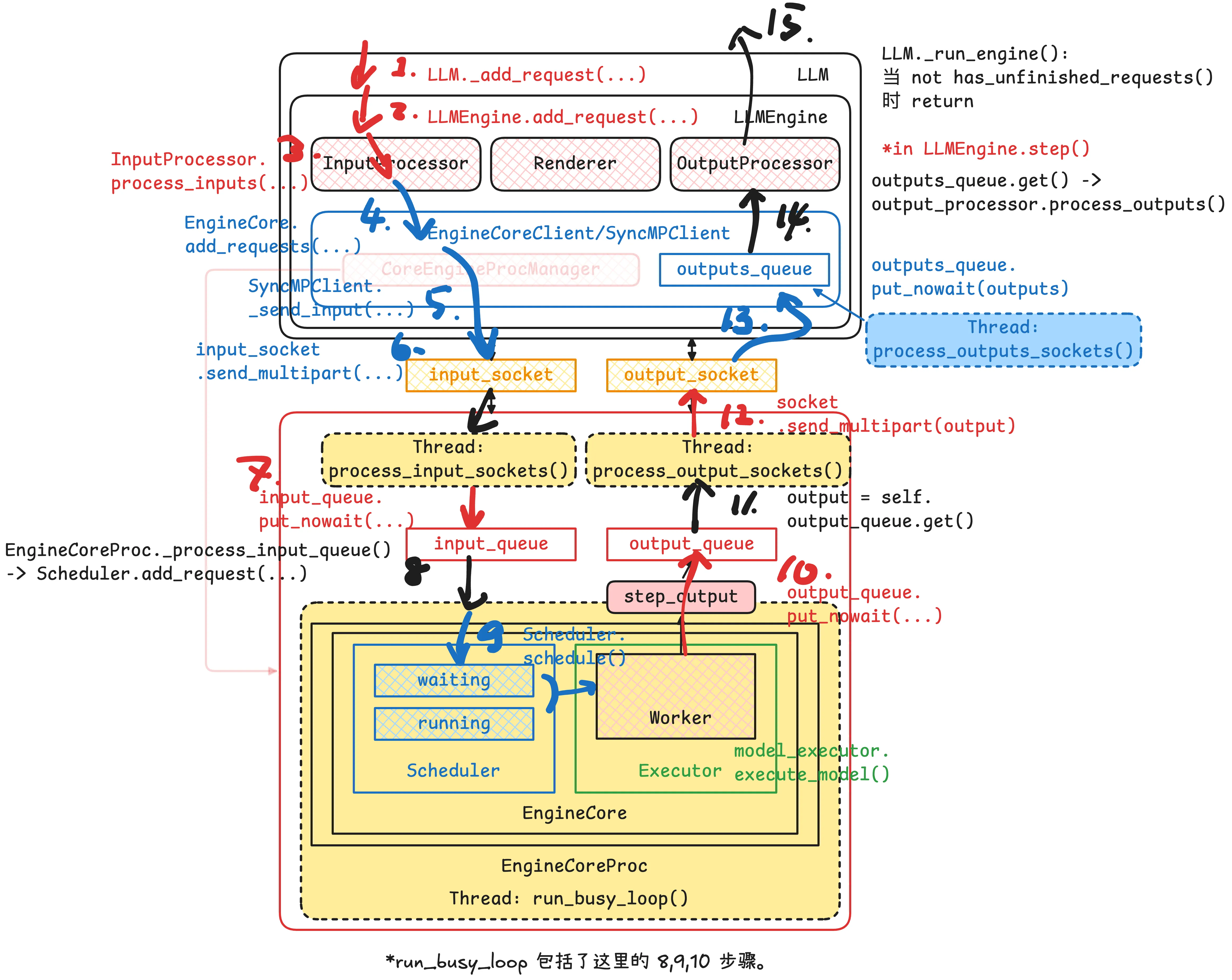
在离线推理阶段,可以用上图来表示所有组件之间的关系。需要注意的是 LLM 框和 EngineCoreProc 分别画在不同的框里,代表两个组件分别在不同的进程之间运行。正如下文将会看到,两个进程需要进行通信,通过 Python ZMQ:消息传递库 实现,以及通过 input_socket 和 output_socket 进行通信。图中 CoreEngineProcManager 指向 EngineCoreProc 的箭头表示 CoreEngineProcManager 负责维护这个进程的生命周期、上下文管理等。
初始化阶段
LLM
- 推理系统的初始化全部藏在
LLM(...)之后。 - 进入
LLM.__init__(...)初始化函数 - 在参数封装成
EngineArgs之后,LLM负责初始化LLMEngine
本小节的剩余内容都用来解析第一行是怎么运行的 ;((((
LLM/LLMEngine
LLMEngine.from_engine_args(...)被调用之后会生成并初始化一个LLMEngine实例。这里executor_class=<class 'vllm.v1.executor.uniproc_executor.UniProcExecutor'>- 进入
LLMEngine.__init__(...) - 这里可以看到
LLMEngine有四个关键部件:
renderer:负责把用户输入渲染成模型可接受的 prompt 形式,例如应用chat_template、处理 tokenizer/detokenizer 相关逻辑等。这里暂不展开。input_processor:负责把外部传入的prompt + params转换成EngineCoreRequest。也就是说,它把“用户视角的请求”整理成“调度与执行系统能理解的请求”。output_processor:负责把EngineCore返回的低层输出转换成最终的RequestOutput/PoolingRequestOutput。它还维护请求状态,例如流式输出、停止条件、完成请求、需要 abort 的请求等。engine_core:重头戏。它接收EngineCoreRequest并返回EngineCoreOutput。这里我们 step intoEngineCoreClient.make_client(...)看它怎么构造一个实际负责推理的engine.
NOTE这里
EngineCoreClient.make_client(...)会返回一个EngineCoreClient。在 multiprocess 模式下,LLMEngine实际并不直接持有真正执行推理的EngineCore,而是通过EngineCoreClient间接与EngineCoreProc交互。
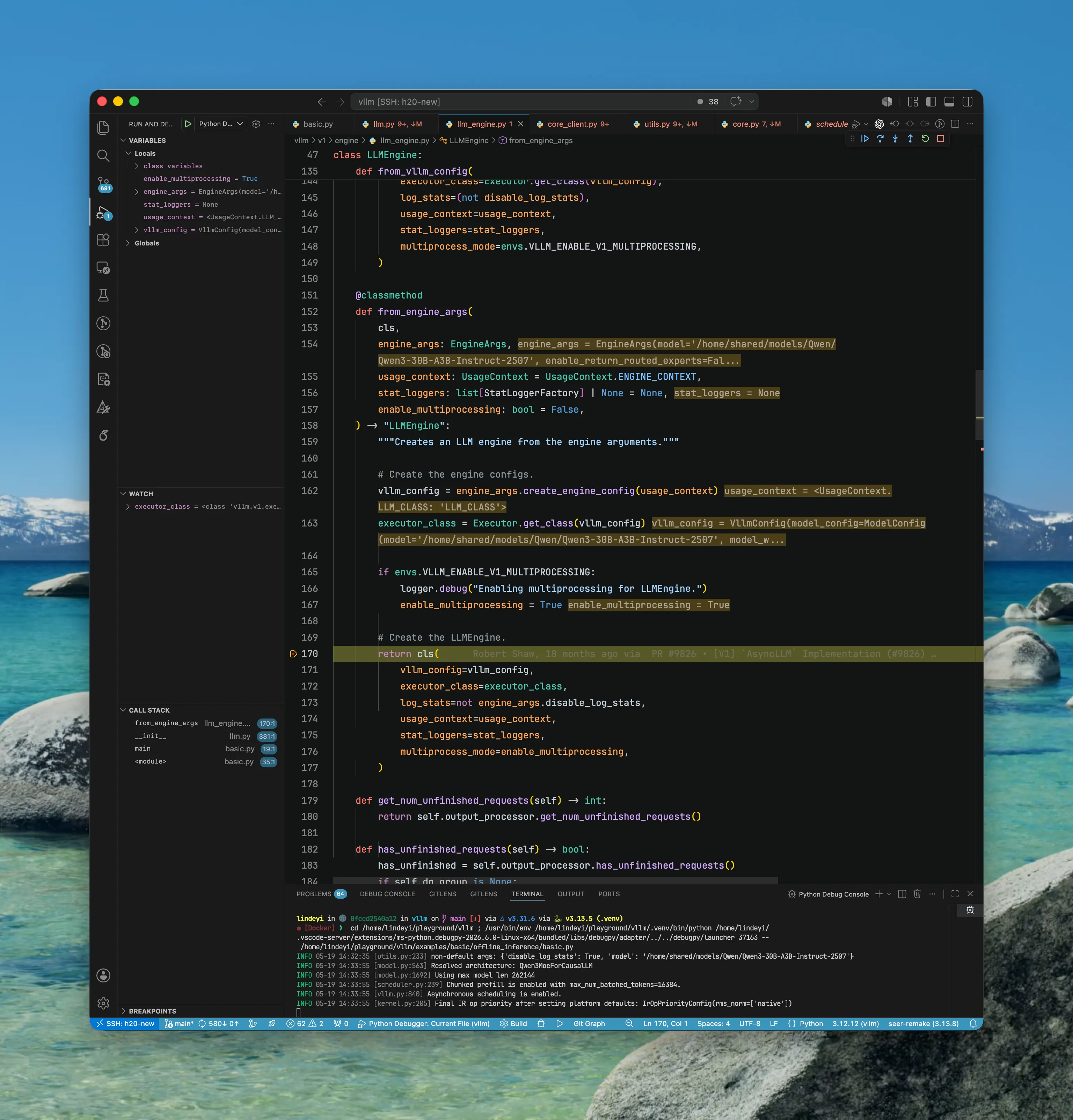
可以看到 LLMEngine 的 engine_core 变量事实上是个 Client 对象。
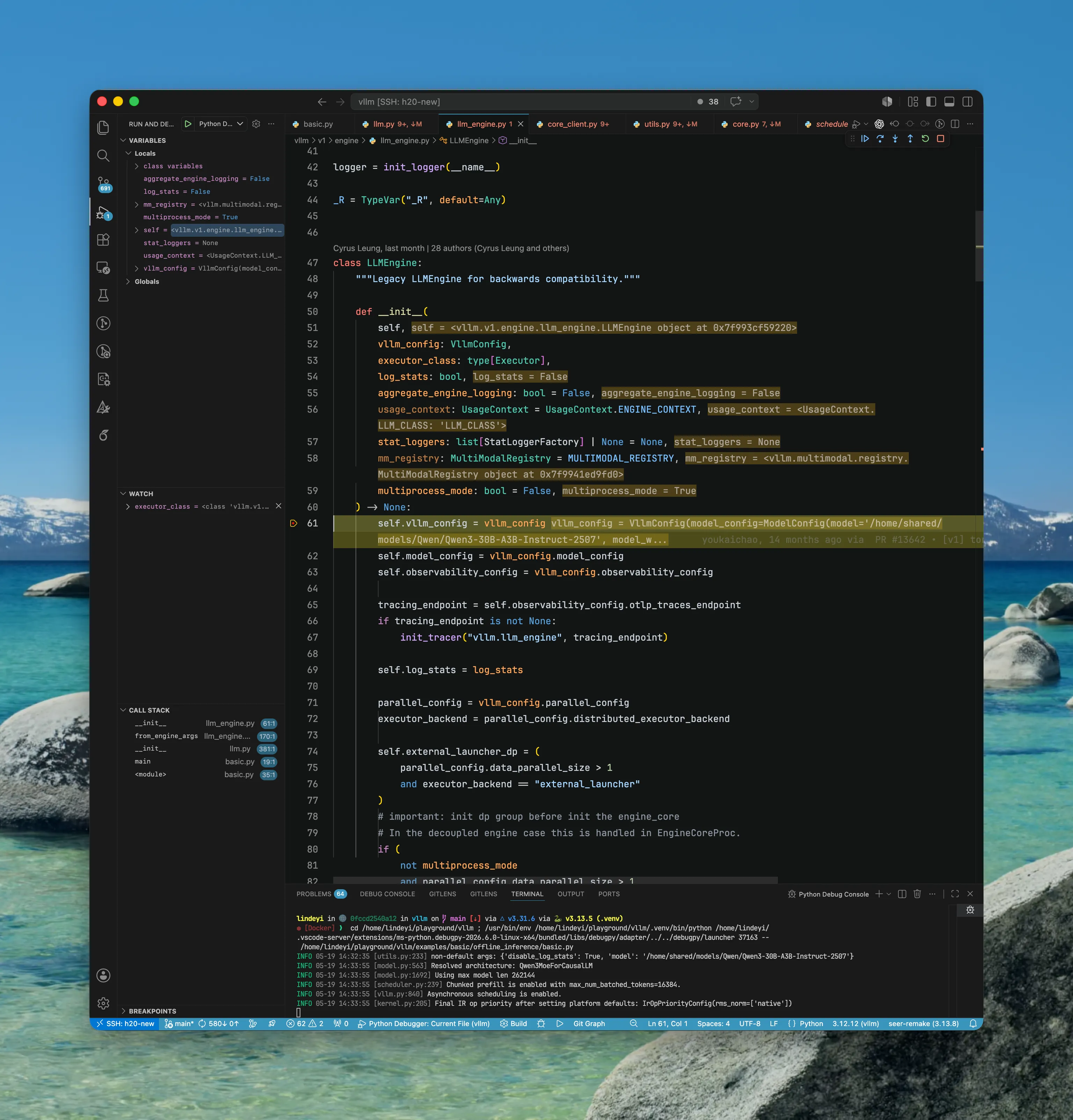
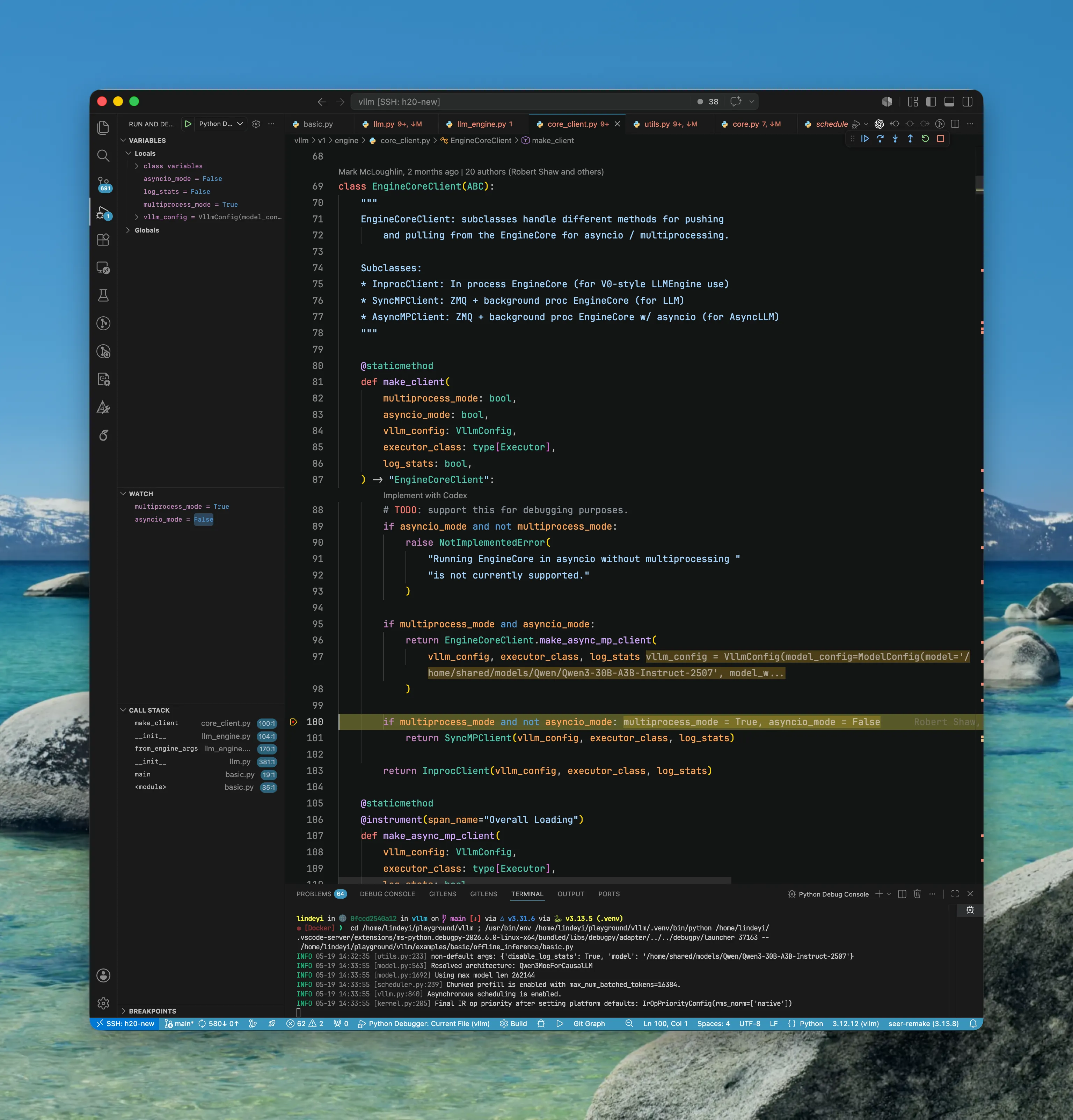
LLM/LLMEngine/EngineCoreClient (SyncMPClient)
EngineCoreClient可以理解为LLMEngine与底层EngineCore之间的代理层。 它对上向LLMEngine暴露统一接口,对下则根据运行模式决定:- 单进程模式:直接调用本地
EngineCore - 多进程模式:spawn 一个
EngineCoreProc子进程,并通过 ZMQ/IPC 与其通信 - 在目前的配置下,
EngineCoreClient启动SyncMPClient。
- 单进程模式:直接调用本地
SyncMPClient会首先进行MPClient的初始化- 这里可以关注一下在
MPClient中初始化的注释。
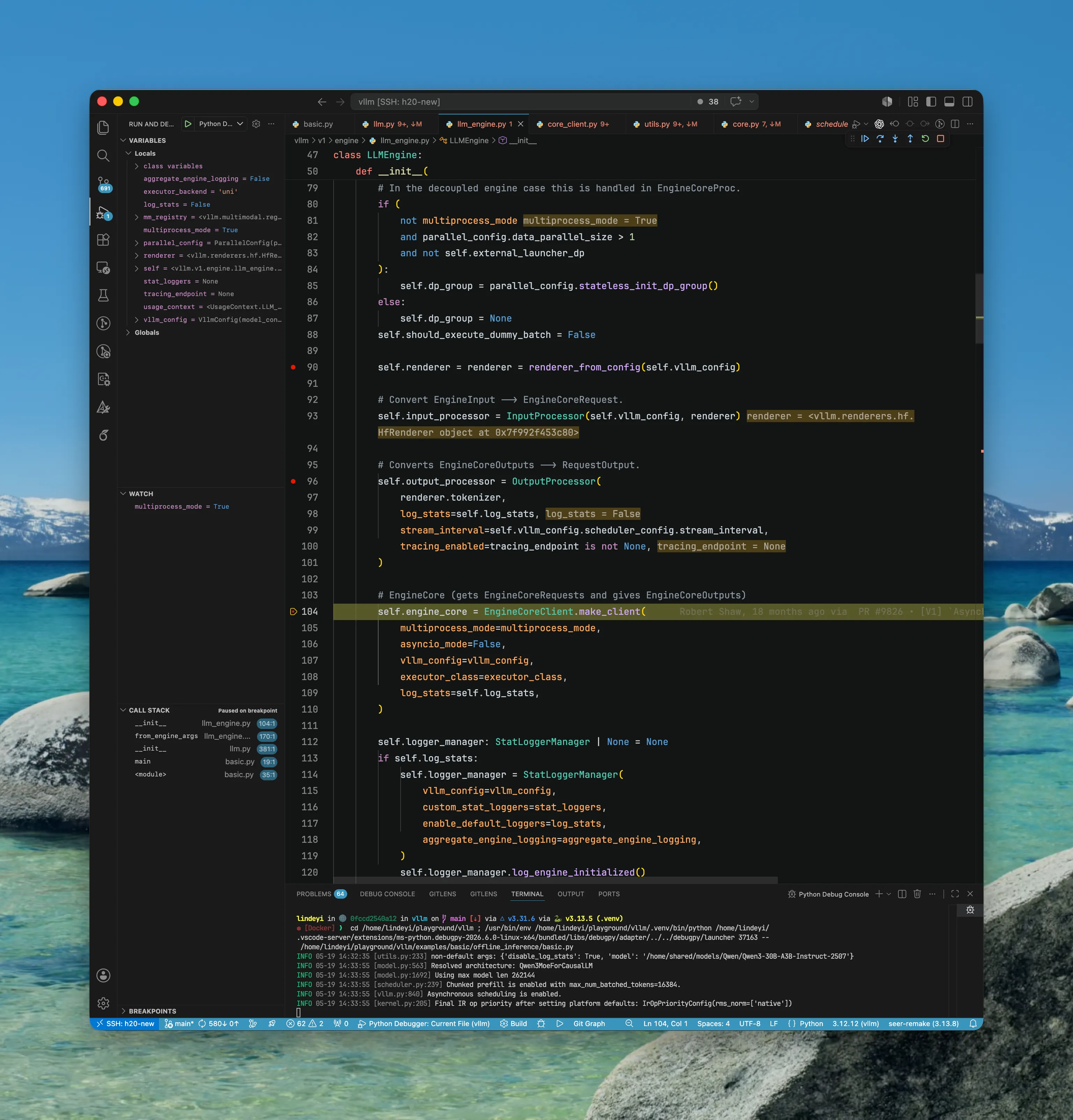
【重点】下面两张图相当重要.在 multiprocess 模式下,MPClient 首先创建两条 ZMQ 通信通道:
input_socket:前端请求通道。它是一个ROUTERsocket,绑定在addresses.inputs[0]上,用来向后端EngineCoreProc发送EngineCoreRequest、abort 请求和 utility call。output_socket:后端输出通道。它是一个PULLsocket,用来接收EngineCoreProc返回的EngineCoreOutputs。
随后,launch_core_engines(...) 会启动真正的后端 EngineCoreProc。注意这里传递的不是 socket 本身,而是同一组 addresses。也就是说,前端和后端并不共享 ZMQ Context 或 socket object,而是各自在自己的进程中创建 socket,并通过相同的 address 建立连接。
【为什么 input_socket 用 ROUTER,而 output_socket 用 PULL?】因为两个方向的通信需求不同。
- 在请求发送方向,frontend 可能连接多个
EngineCoreProc,并且需要根据engine_identity指定请求发给哪个 engine。因此input_socket使用ROUTER,让 frontend 具备定向路由和多 engine 调度能力。 - 而在输出返回方向,backend 不需要再做复杂路由;任意
EngineCoreProc只要生成了EngineCoreOutputs,直接通过PUSH推回 frontend 即可。frontend 只需要用PULL汇聚所有 engine 返回的输出。
LLM/LLMEngine/EngineCoreClient/CoreEngineProcManager
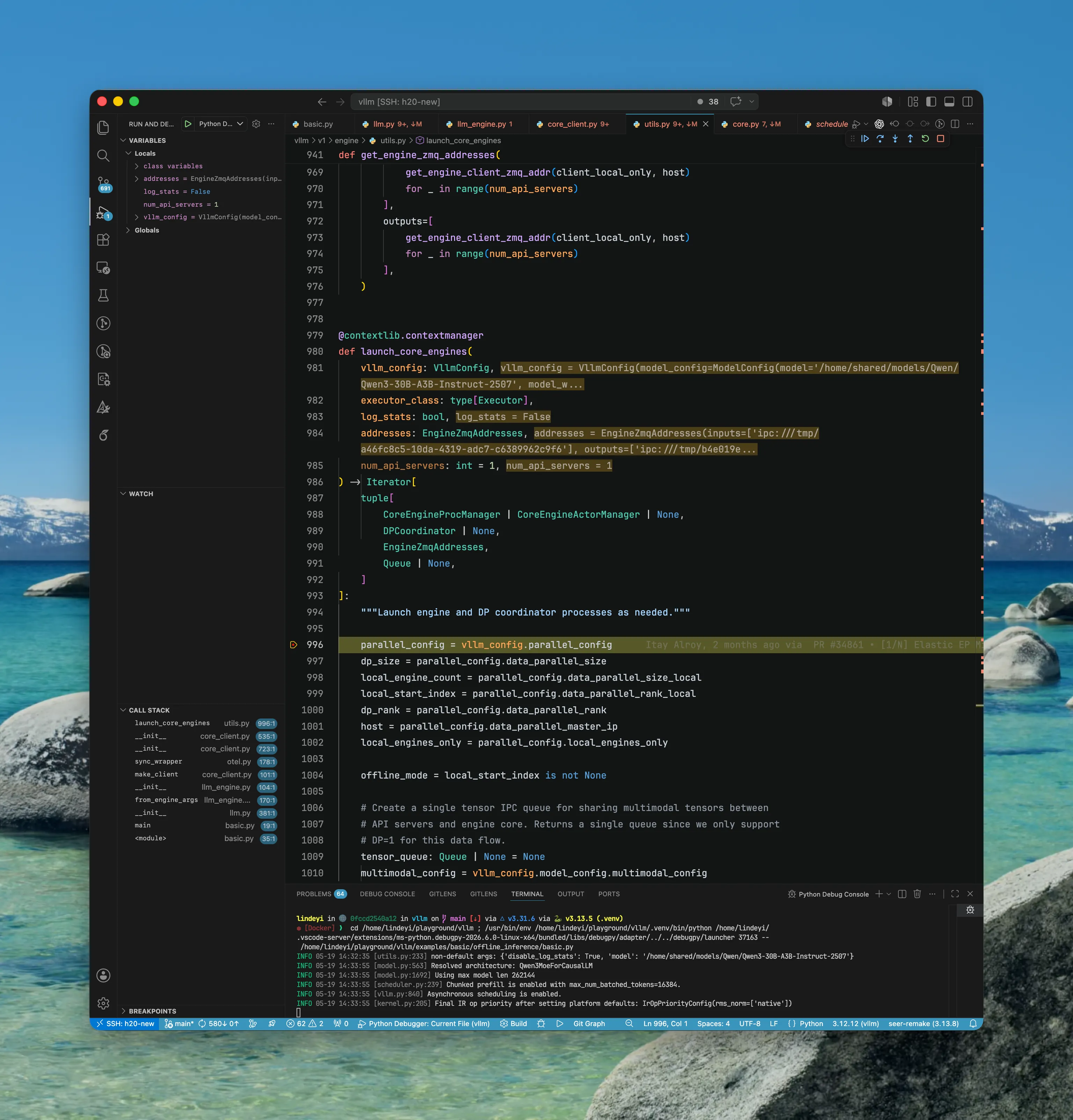
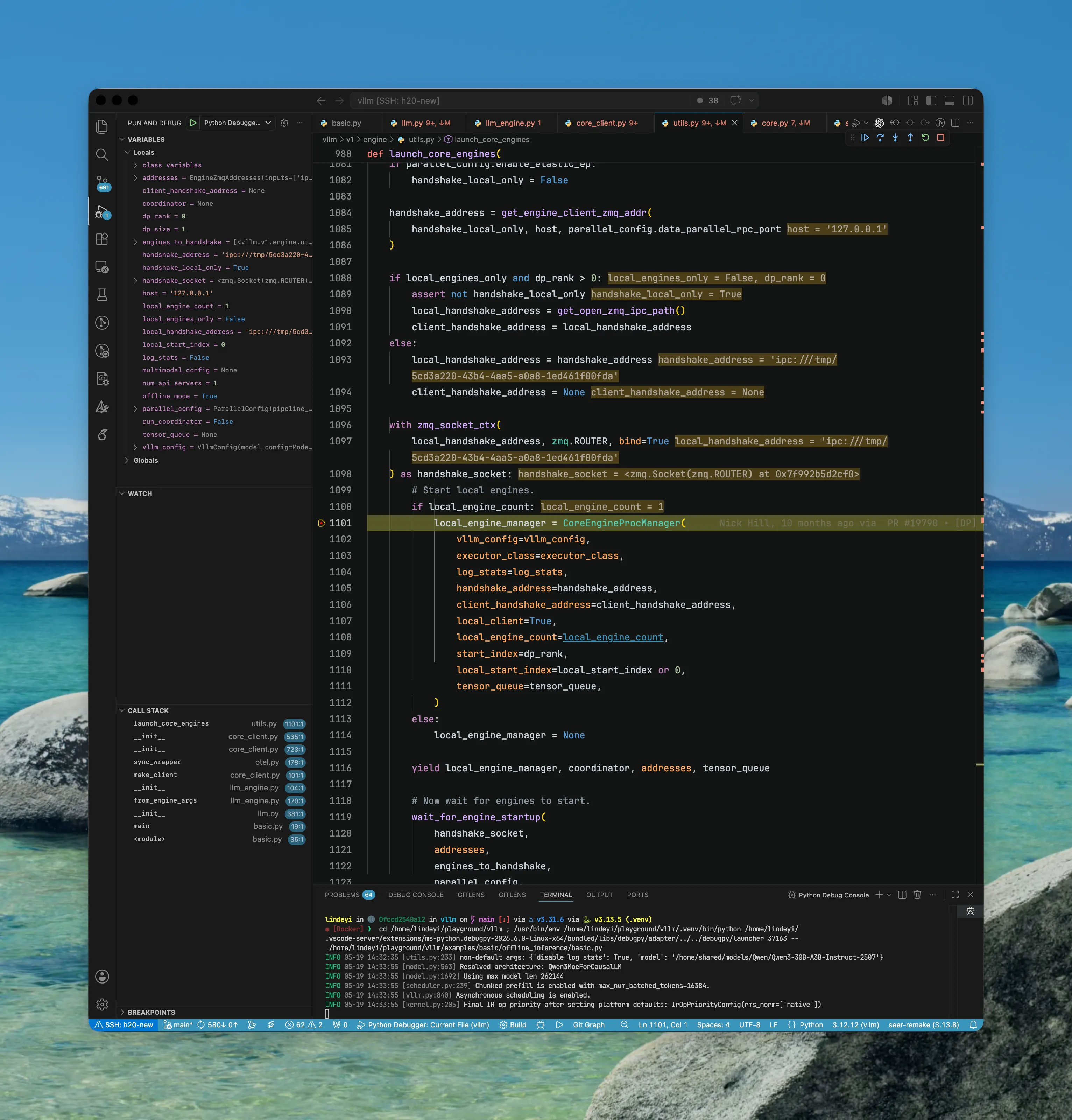
这里进入 launch_core_engines(...) 函数。
- 这个函数会创建一个
CoreEngineProcManager对象,专门负责创建一个或多个(在多 DP/TP 等场景下)EngineCoreProc实例、其运行环境配置以及生命周期管理,避免孤儿进程以及EngineCoreProc意外死亡等 - 这个函数不属于
EngineCoreClient (SyncMPClient) - 生成的
CoreEngineProcManager是返回给EngineCoreClient (SyncMPClient)持有(结合前文第二张图和后文可以看到)。
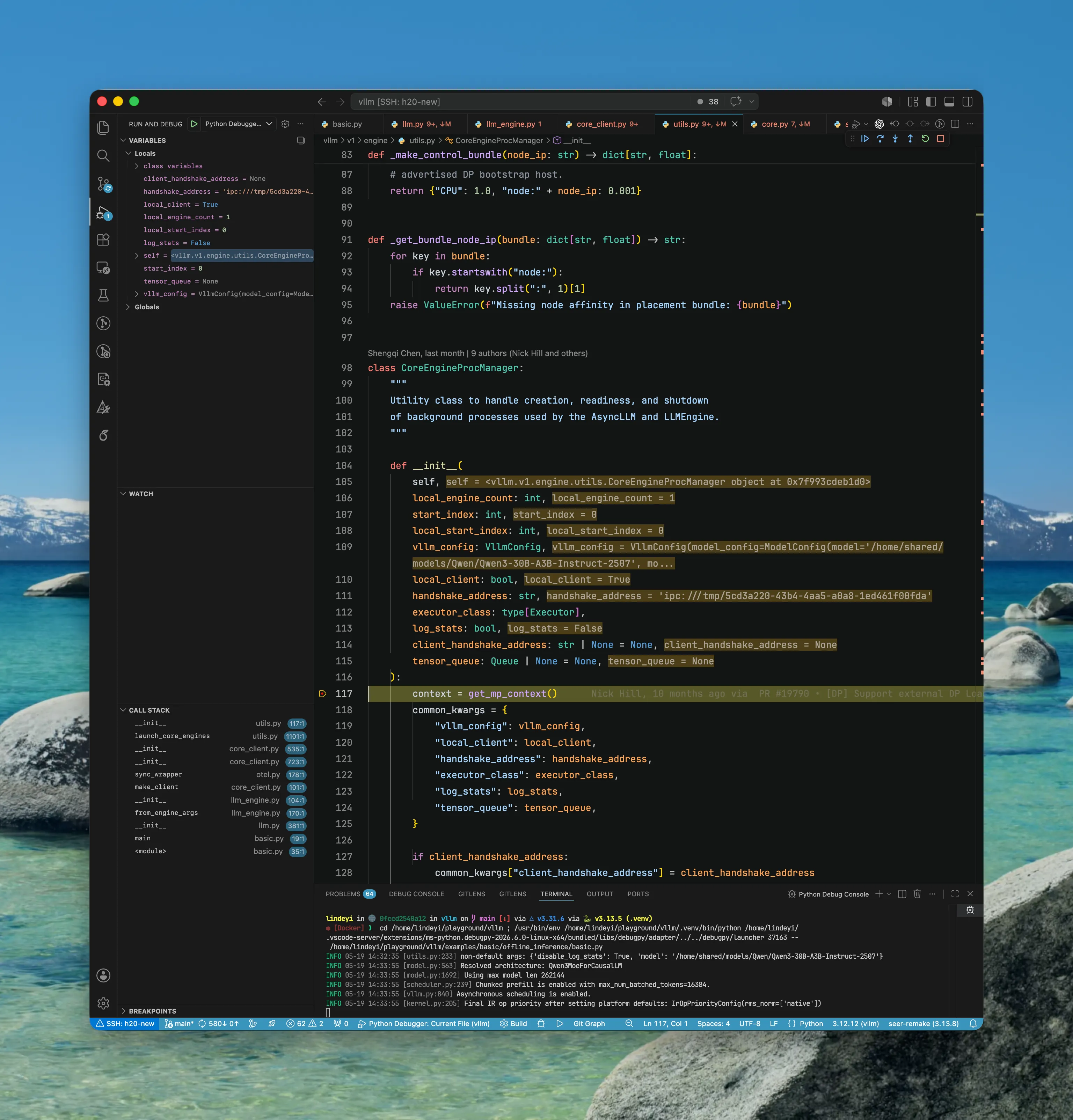

EngineCoreProc
- 这里
EngineCoreProc进程已经被创建出来,我们切换到EngineCoreProc进程查看运行情况。 - 在读取配置后创建
EngineCoreProc(...)对象
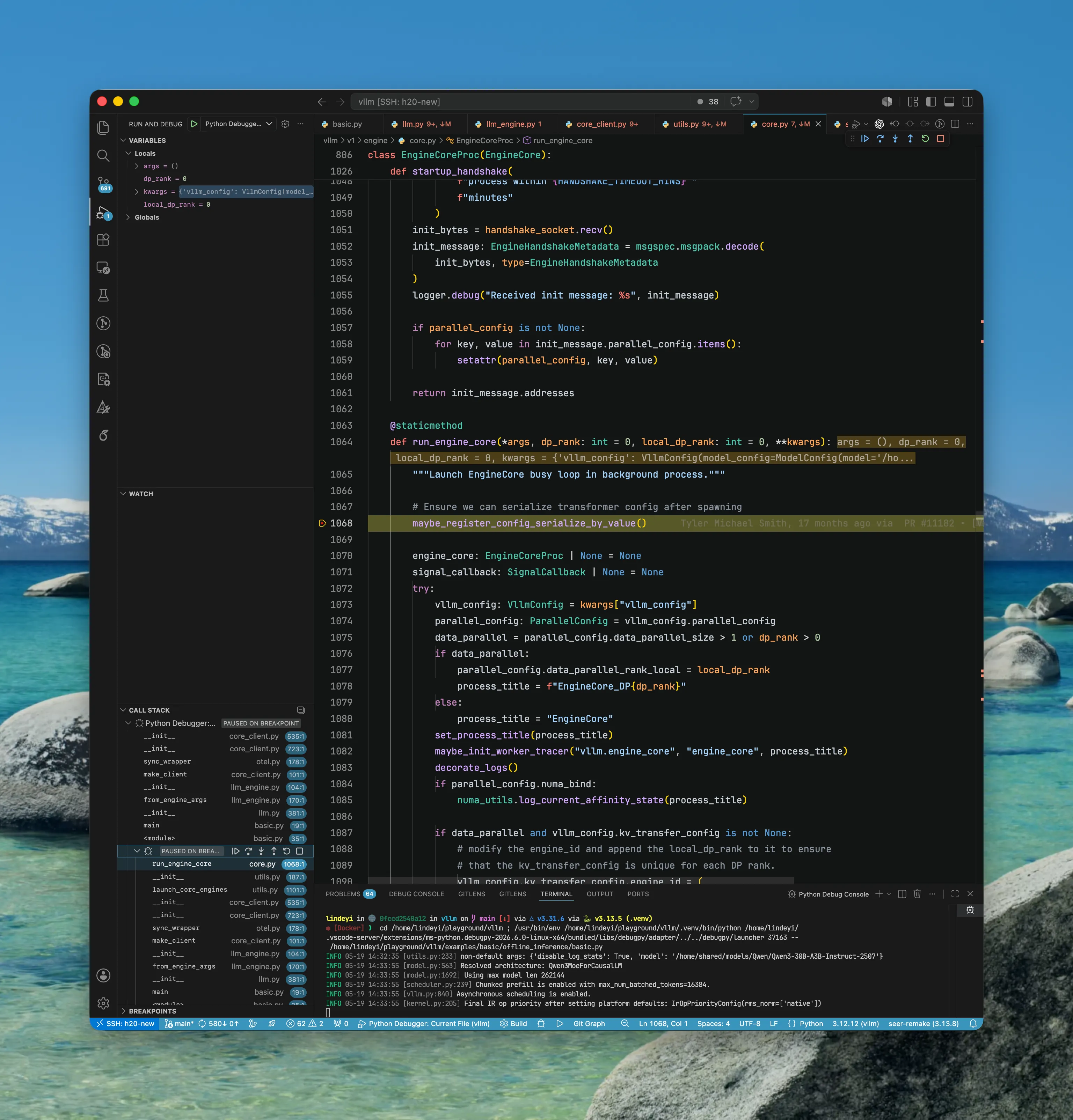
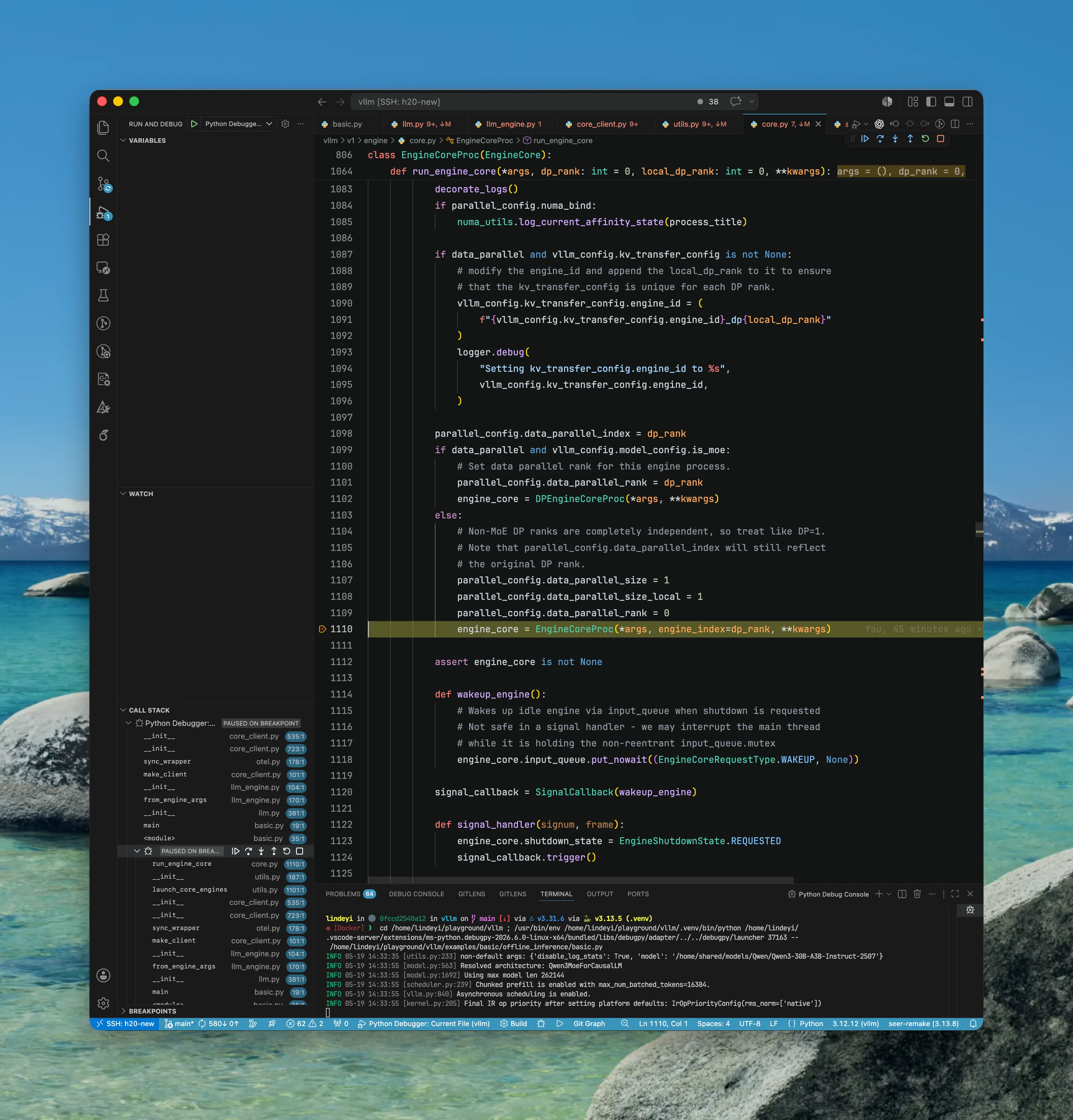
分别创建 self.input_queue 和 self.output_queue 对象。
- 这两个对象是
EngineCoreProc与从上层EngineCoreClient交互的重要接口,用于获取/写入数据 - 分别有独立线程
process_{input/output}_sockets(...)处理(我们将会看到)
具体而言:
input_queue用于缓存从 ZMQ socket 接收到的请求,由后台线程process_input_sockets(...)持续接收、反序列化并写入队列,随后由run_busy_loop()主循环读取并处理。output_queue用于缓存EngineCore产生的推理输出,由主循环写入,再由后台线程process_output_sockets(...)负责序列化并通过 ZMQ socket 发回EngineCoreClient。
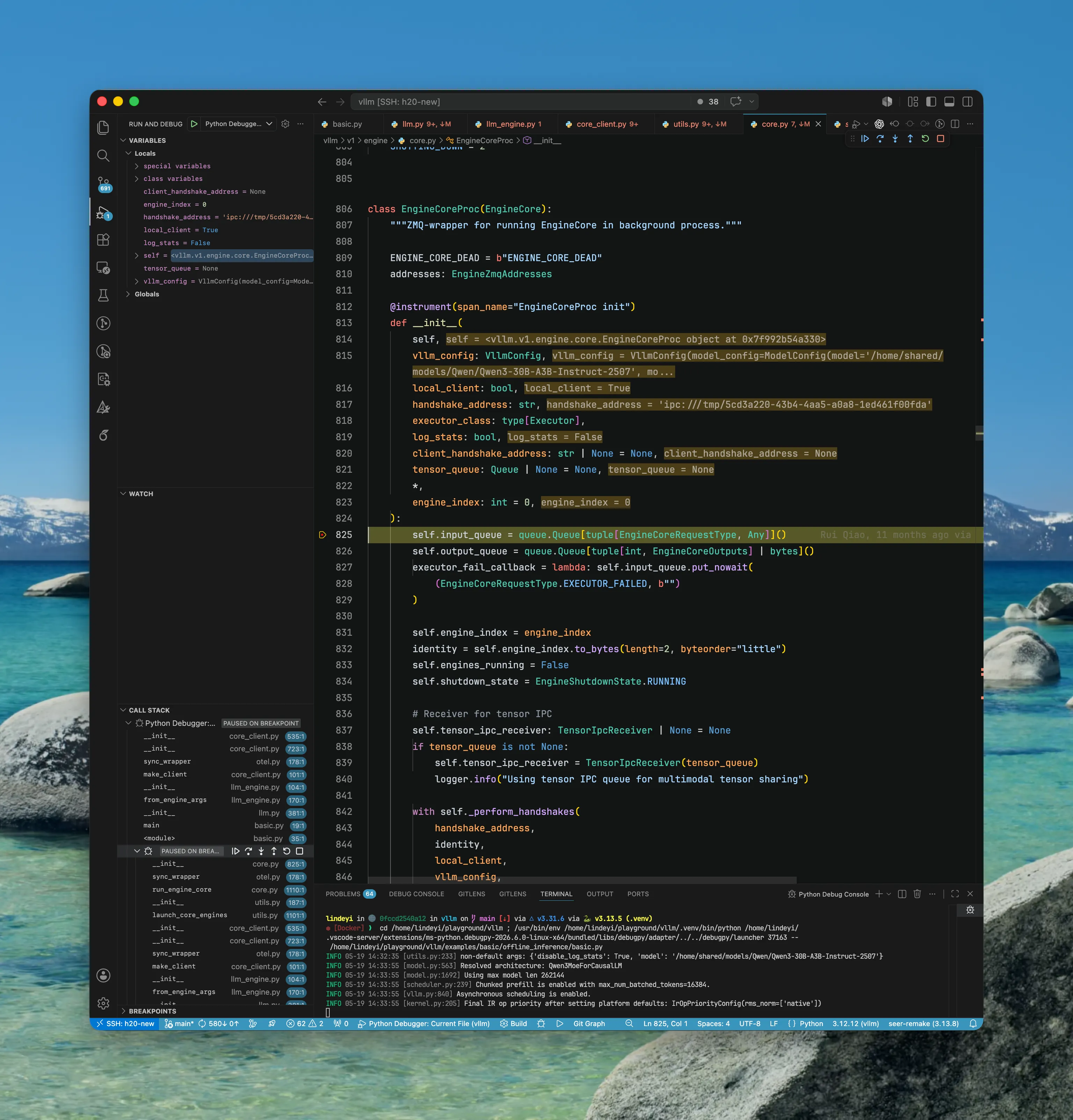
在 EngineCoreProc 的初始化中,触发 EngineCore 的初始化
- 如何理解这两个元件?EngineCoreProc = EngineCore + ZMQ/Process Wrapper
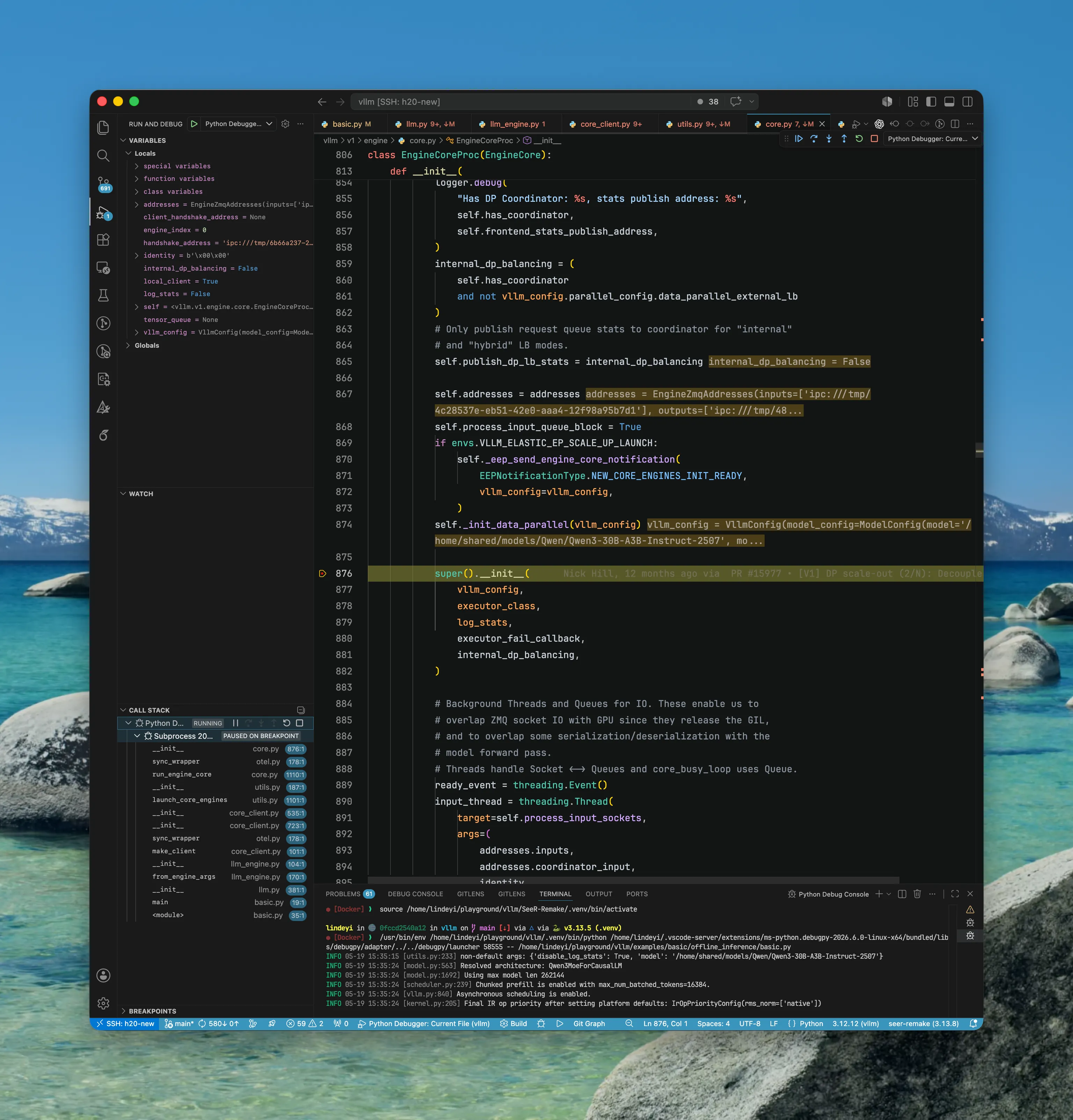
EngineCoreProc/EngineCore/Executor
先初始化 Executor1.
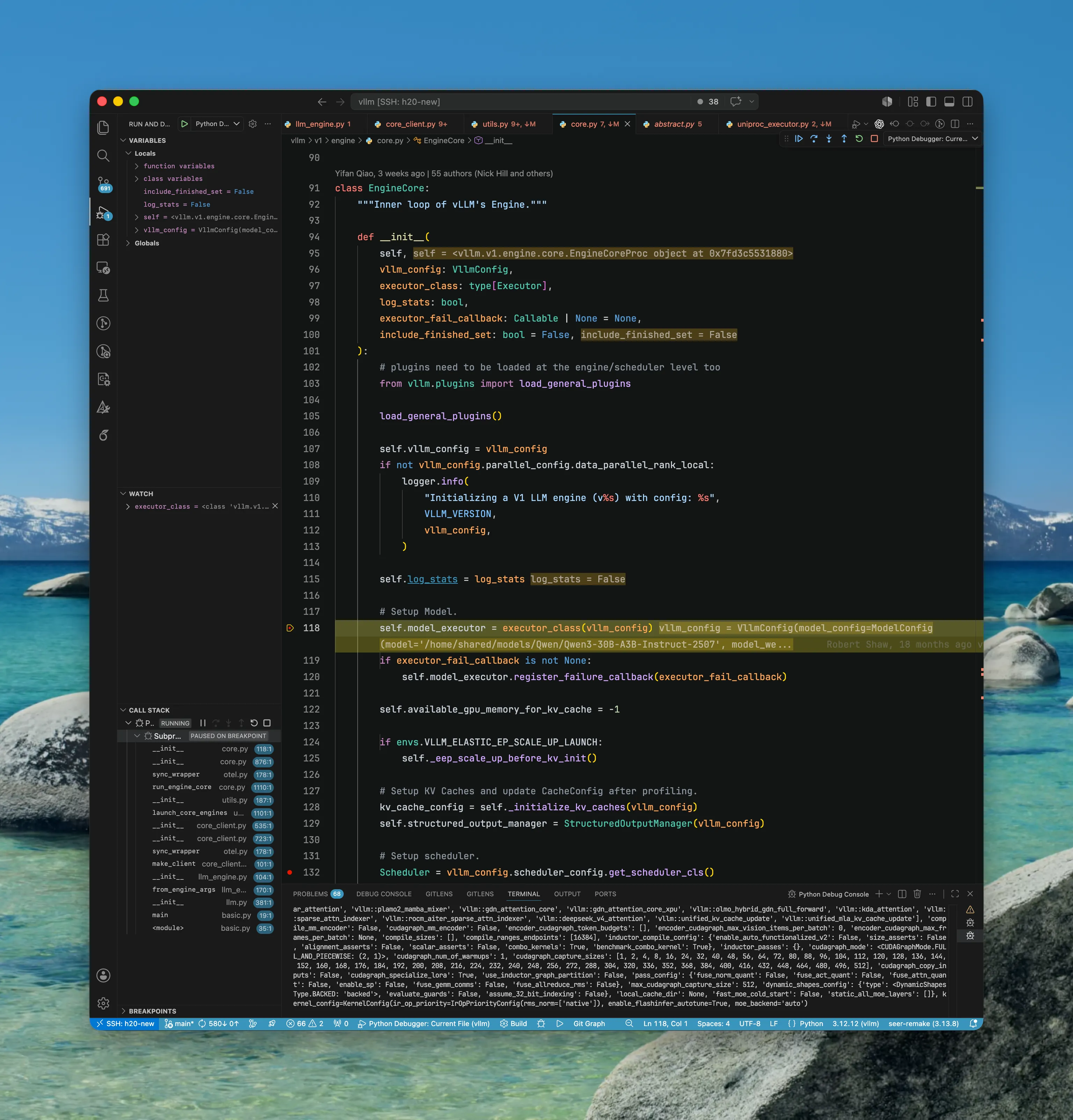
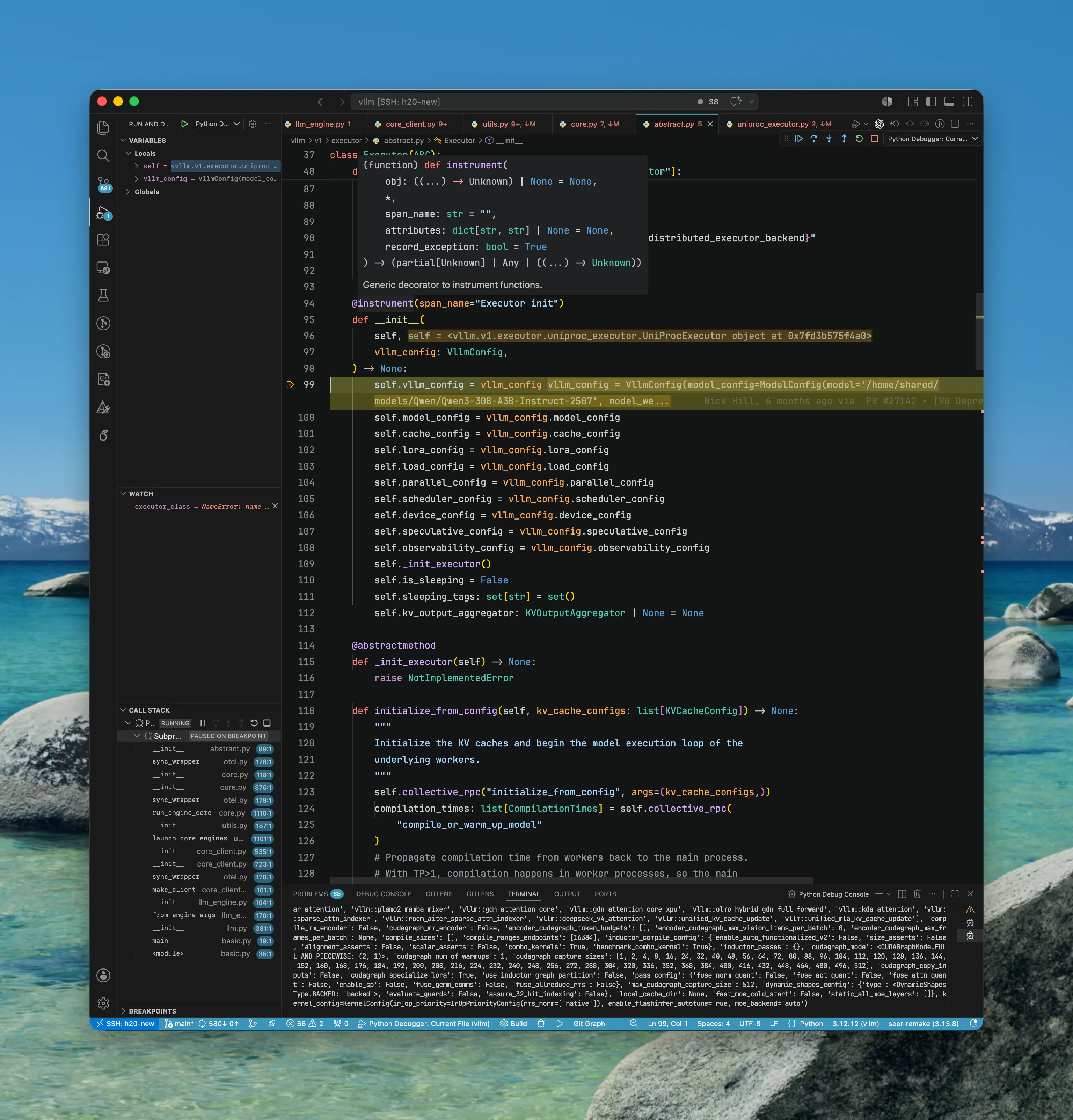
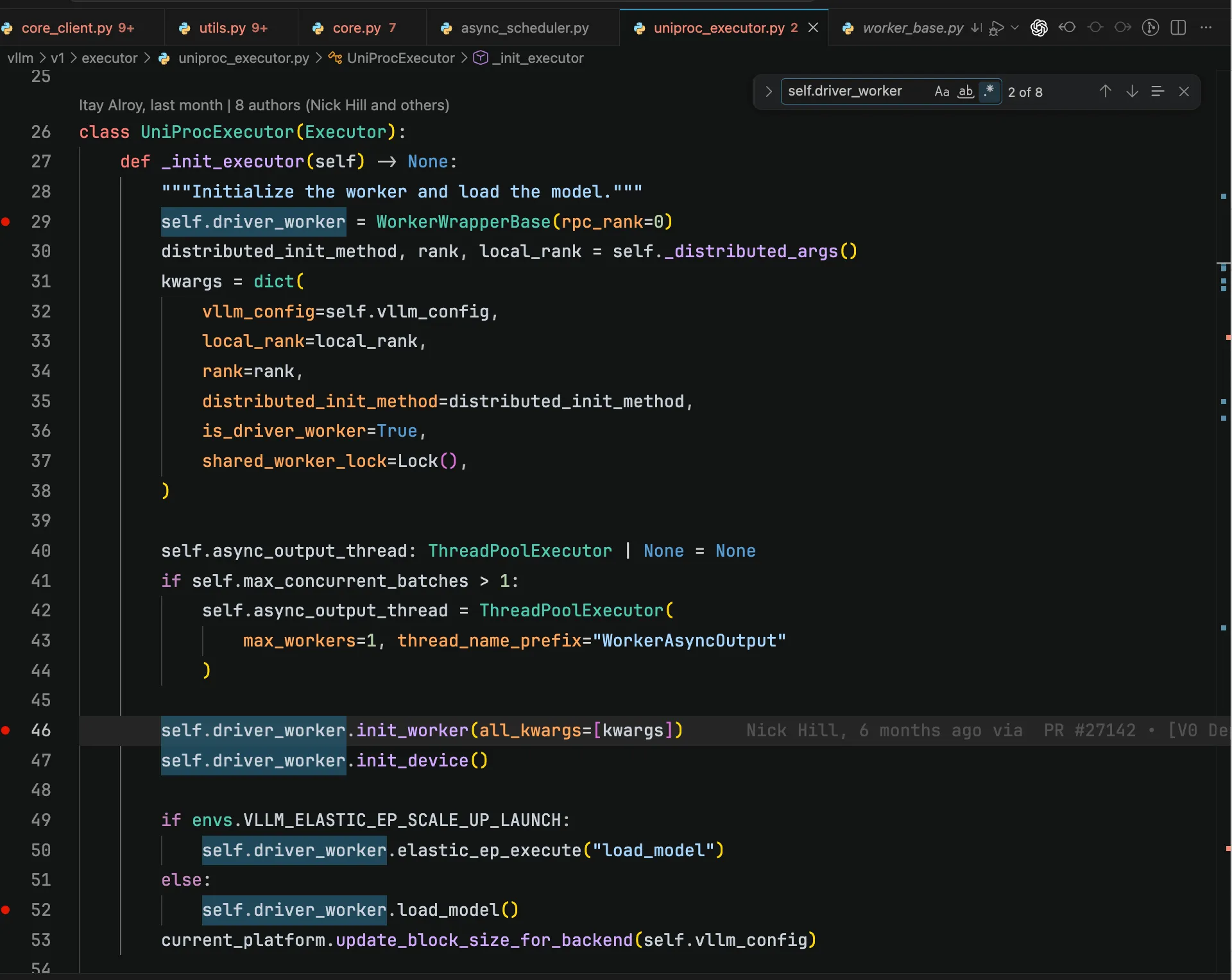
EngineCoreProc/EngineCore/Executor/Worker
再由 Executor 初始化 Worker,由 Worker 完成模型加载。2
EngineCore vs Worker这里其实已经可以看到,vLLM 系统里存在两层并行。
第一层是外层的 EngineCore 并行。每个
EngineCore可以看作一个相对独立的推理副本,拥有自己的 scheduler、KV cache 管理器以及一组模型执行 worker。因此在 DP 场景下,不同EngineCore通常对应不同的 DP replica / DP rank:它们加载相同的模型副本,处理不同的请求流,这正好符合推理阶段 data parallelism 的 embarrassingly parallel 特性。第二层是内层的 Worker 并行。
Worker是模型执行层的基本计算单元,通常对应一个 GPU/distributed rank,并参与 TP、PP、EP 等模型并行组。也就是说,TP/PP/EP 主要发生在一个EngineCore内部的 worker group 之间:这些 workers 共同完成一次模型 forward,而外层的多个EngineCore则负责复制这套执行能力来承接更多请求。因此可以粗略理解为:
DP复制的是EngineCore + Worker group;TP/PP/EP切分的是单个EngineCore内部的Worker group。
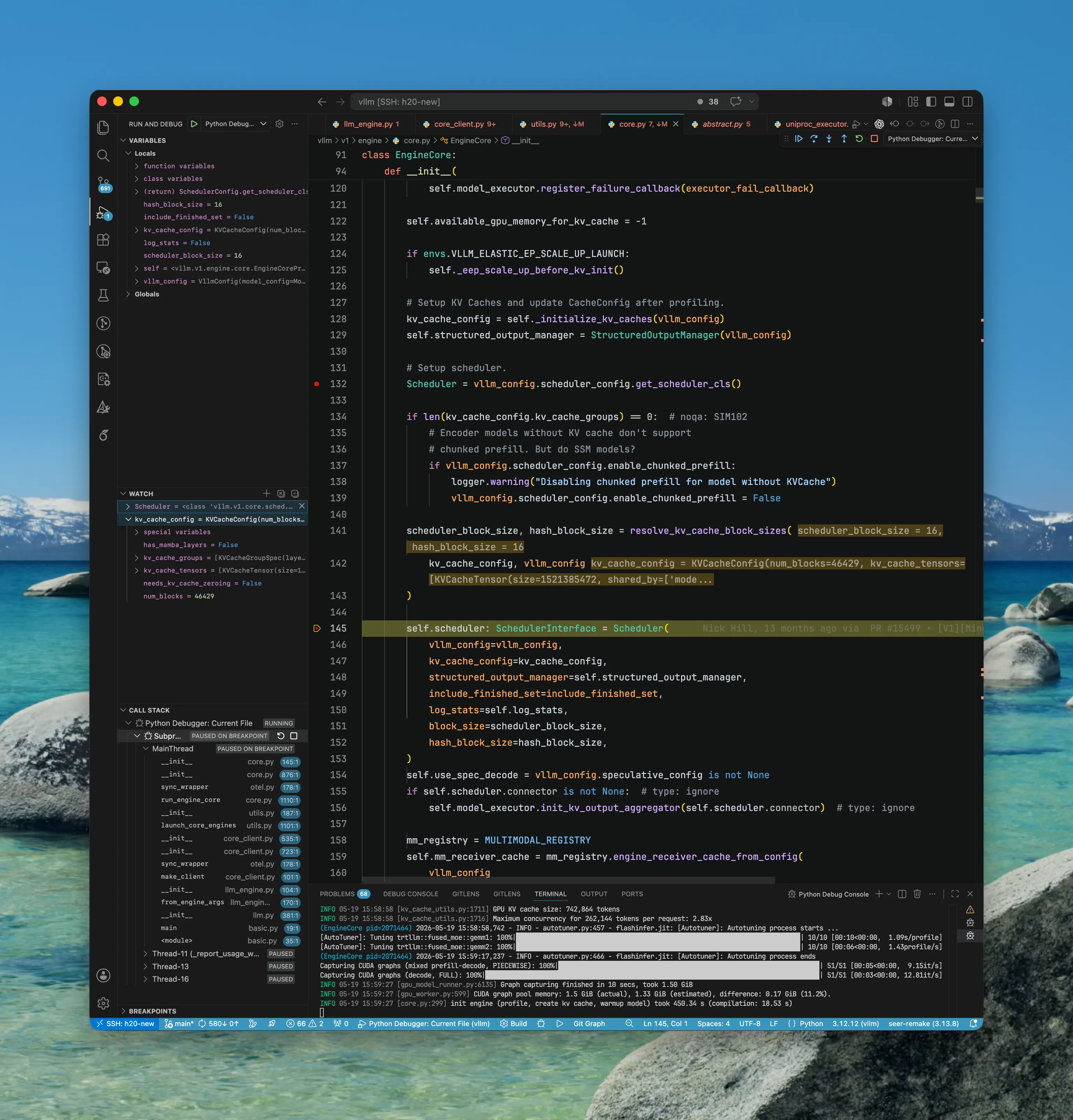
EngineCoreProc/EngineCore/Scheduler
完成 Executor 的初始化之后,还有控制面的 Scheduler 需要初始化。这里通过 debug 可以看到 Scheduler 的类型是 <class 'vllm.v1.core.sched.async_scheduler.AsyncScheduler'>
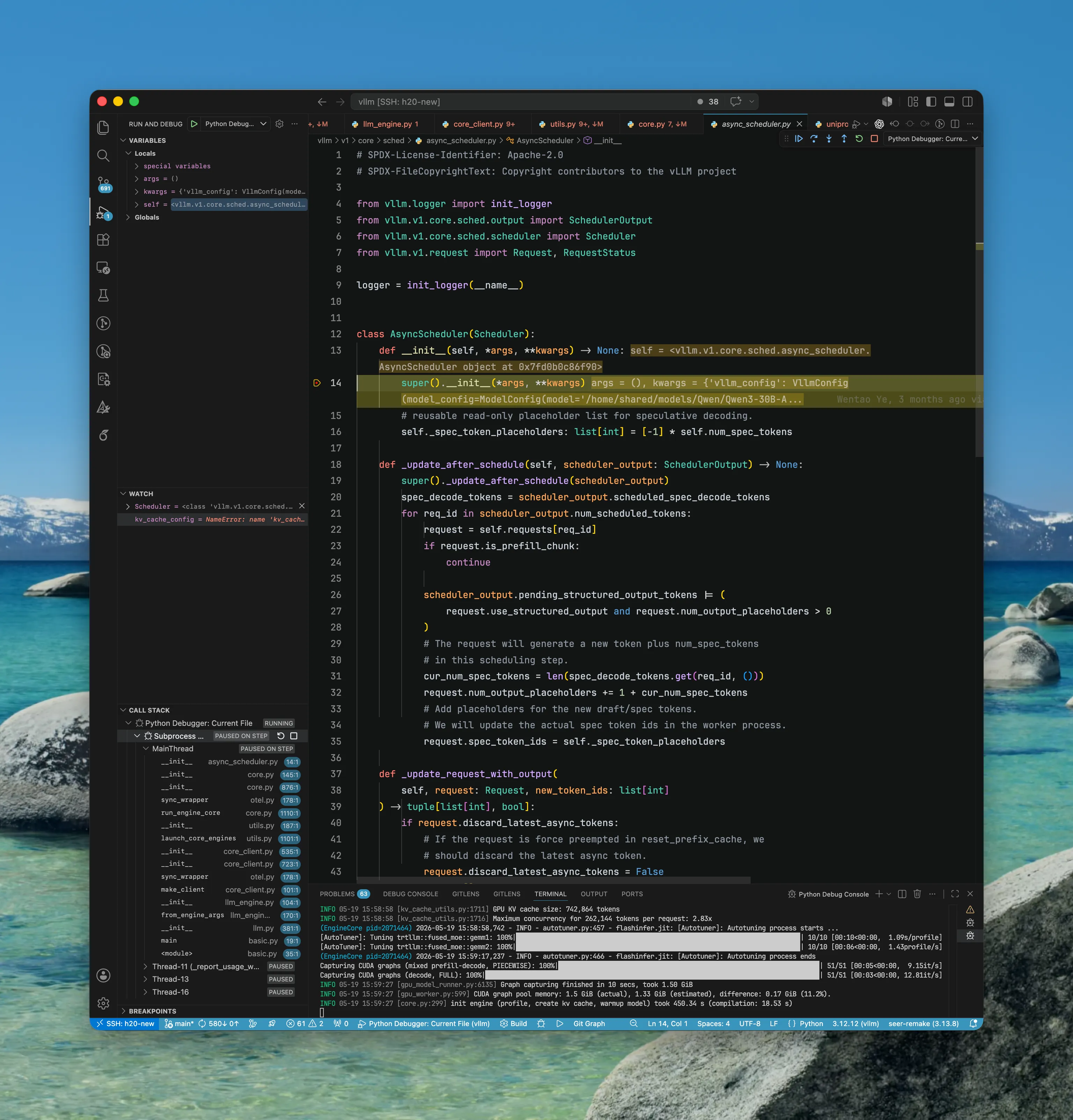
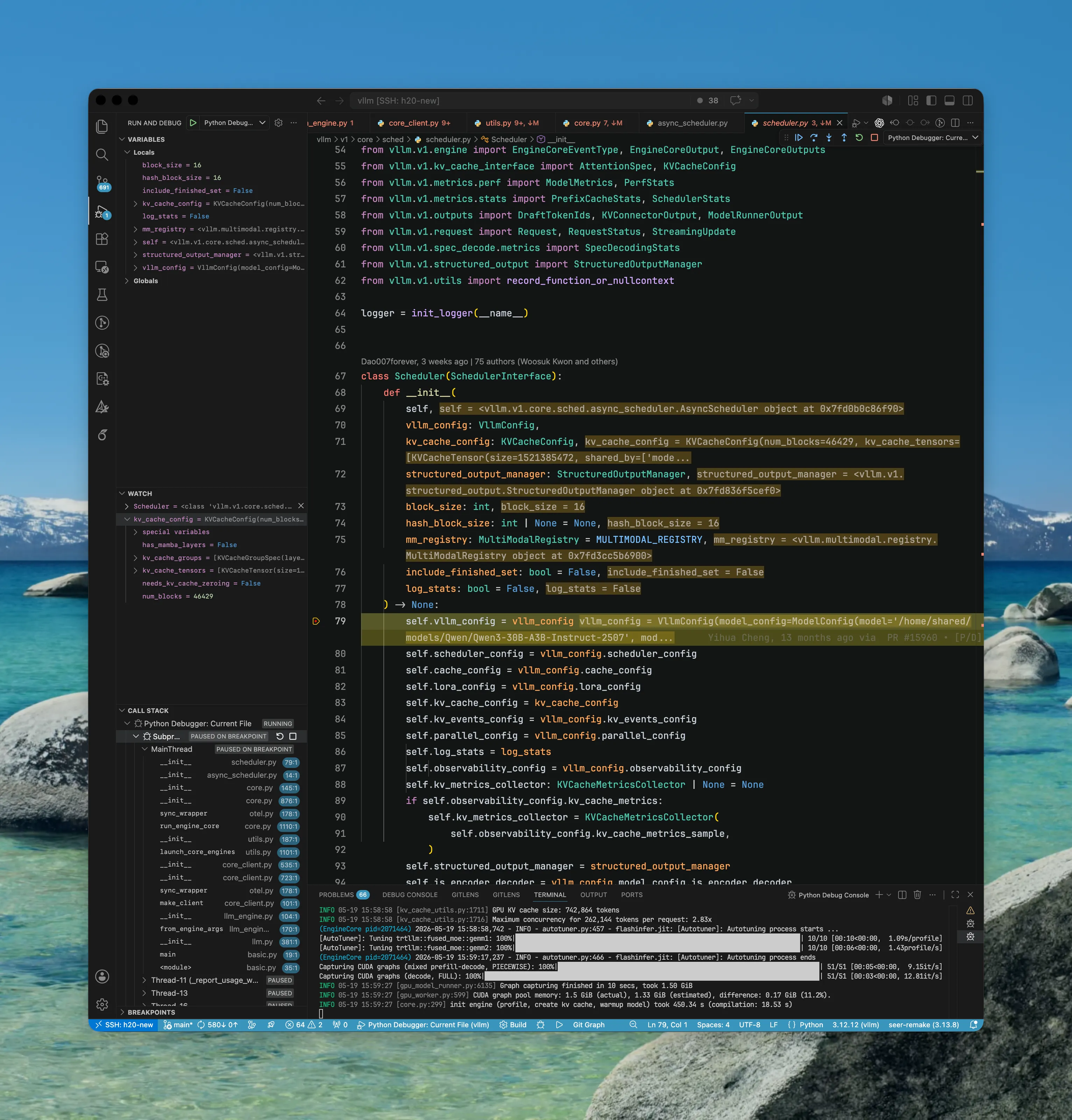
EngineCoreProc Threads
EngineCoreProc (EngineCore): 最后,处理 input_queue 和处理 output_queue 分别由对应的 thread 处理
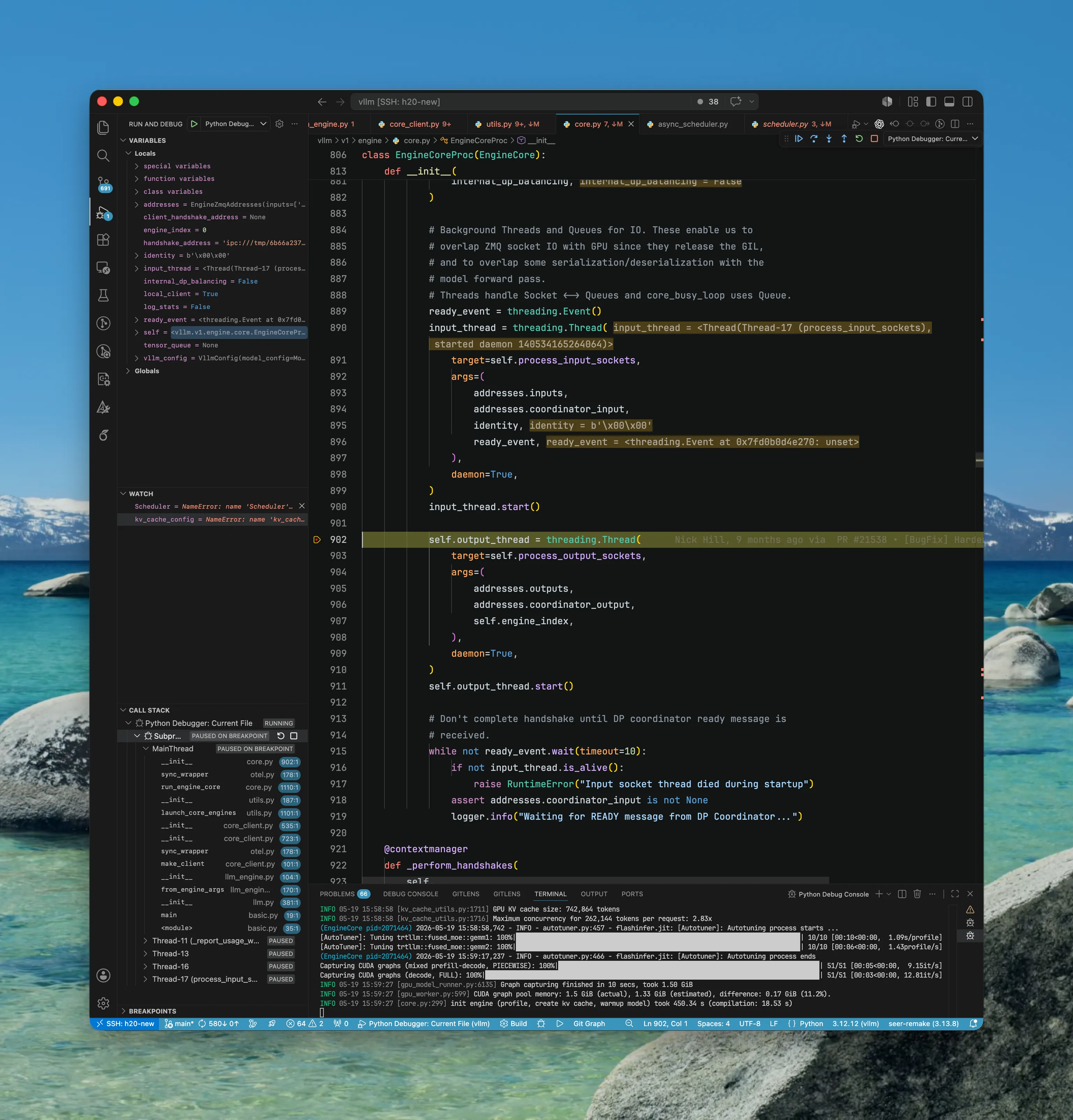
以上完成全部初始化的步骤
推理阶段
接下来从 LLM.generate(...) 开始进入真正的推理流程。
总体而言,可以分成 15 个步骤:
以下所有的方法我都标注了类名(而不是 self)以方便读者查阅。
下面段落我让 GPT 帮我标注了一下对应 vLLM GitHub 仓库代码位置,感谢大模型🙏
请求提交
LLM.generate(...)
|--- LLM._run_completion(...)
|--- LLM._add_completion_requests(...)
| |--- LLM._render_and_add_requests(...)
| |--- LLM._add_request(...)
| |--- LLMEngine.add_request(...)
| |--- LLMEngine.input_processor.process_inputs(...)
| | |--- return EngineCoreRequest
| |
| |--- LLMEngine.output_processor.add_request(...)
| | |--- 在主进程登记 request 状态
| |
| |--- LLMEngine.engine_core.add_request(...)
| |--- SyncMPClient.add_request(...)
| |--- SyncMPClient._send_input(...)
| |--- SyncMPClient.input_socket.send_multipart(...)在
LLM.generate(...)时会调用LLM._run_completion(...)- 因此会调用
LLM._add_completion_requests(...)和LLM._run_engine(...) - 先看
LLM._add_completion_requests(...),会先调用LLM._render_and_add_requests(...) - 接着对每个请求调用
LLM._add_request(...)
这里可以把
LLM.generate(...)理解成离线推理 API 的入口函数。它本身并不直接执行模型 forward,而是把整个流程拆成两部分:先把用户传入的 prompts、sampling params 等输入转成内部请求并提交给 engine;然后再启动 engine 循环,不断取回输出,直到所有请求完成。- 因此会调用
LLM._add_request(...)时会调用LLMEngine.add_request(...)这一层开始从
LLMAPI 层进入LLMEngine层。LLM更像是用户侧的封装,而LLMEngine才是真正负责管理请求生命周期、输出处理器以及底层EngineCore通信的核心对象。在
LLMEngine.add_request(...)中,执行LLMEngine.input_processor.process_inputs(...),返回一个EngineCoreRequest对象3这一步的核心作用是把 API 层输入转换成
EngineCore能理解的请求格式。也就是说,用户传入的 prompt、sampling params、LoRA request、priority 等信息,会在这里被整理成统一的EngineCoreRequest,为后面跨进程传输和调度执行做准备。同样仍然是在
LLMEngine.add_request(...)中,接着执行下面两行:LLMEngine.output_processor.add_request(request, prompt_text, None, 0)这一行是先登记这个 request 的状态,以使得完成推理之后能够根据request_id找到对应的 detokenizer、logprobs processor、输出模式等。LLMEngine.engine_core.add_request(request)也就是由EngineCoreClient去将这个请求发送给实际执行推理的EngineCoreProc
这里其实有一个非常重要的双登记动作:一方面,
output_processor要先知道这个请求的存在,否则后面模型算完返回 token 时,主进程不知道如何还原成用户需要的RequestOutput;另一方面,engine_core.add_request(...)会把请求真正送到底层执行引擎中。前者负责回来以后怎么处理,后者负责现在送去哪里执行。【准备跨进程】由于
engine_core=SyncMPClient这会调用SyncMPClient.add_request(...),这会调用SyncMPClient._send_input(...)到这里,请求开始离开主进程。
SyncMPClient是主进程侧持有的EngineCoreClient,它的作用不是执行模型,而是把请求序列化并通过 ZMQ socket 发给后台的EngineCoreProc进程。调用
SyncMPClient.input_socket.send_multipart(...),通过input_socket发送出去这里真正发生跨进程通信。请求会被编码成 multipart message,里面包含目标 EngineCore identity、请求类型以及序列化后的请求内容。对于主进程来说,到这一步它已经把任务“投递”出去了;真正的调度、KV Cache 管理、模型 forward 都发生在另一侧的
EngineCoreProc中。
后端执行
EngineCoreProc.process_input_sockets(...)
|--- socket.recv_multipart(...)
|--- deserialize request
|--- EngineCoreProc.input_queue.put_nowait((request_type, request))
EngineCoreProc.run_busy_loop(...)
|--- EngineCoreProc._process_input_queue()
| |--- EngineCoreProc._handle_client_request(...)
| |--- EngineCoreProc.add_request(...)
| |--- EngineCore.scheduler.add_request(...)
|
|--- EngineCoreProc._process_engine_step()
|--- EngineCore.step()
|--- Scheduler.schedule()
| |--- 生成本轮 SchedulerOutput
|
|--- model_executor.execute_model(...)
| |--- 执行本轮模型 forward
|
|--- 生成 EngineCoreOutputs
|
|--- output_queue.put_nowait(outputs)现在我们进入了
EngineCoreProc进程。EngineCoreProc包含了三个线程:process_input_sockets(),process_output_sockets()和run_busy_loop()。首先由process_input_sockets()读取来自input_sockets的数据写入input_queue:EngineCoreProc.input_queue.put_nowait((request_type, request))4process_input_sockets()是一个专门负责 IO 的线程。它并不直接调度请求,而是把 socket 中收到的请求解码之后放入input_queue。这样设计的好处是:ZMQ IO、反序列化、请求预处理和真正的调度执行可以解耦,避免模型执行主循环被 socket IO 细节阻塞。从第 8-10 步是进入
EngineCoreProc.run_busy_loop()的循环:- 会先进行
EngineCoreProc._process_input_queue() - 在函数里面通过
EngineCoreProc._handle_client_request(...)处理请求 - 对
ADD类型请求,最后执行EngineCoreProc.add_request(...),等同于调用EngineCoreProc.scheduler.add_request(...)
run_busy_loop()是EngineCoreProc的主循环,可以把它理解成 vLLM V1 的 engine heartbeat。每次循环会先处理输入队列,把新来的请求加入 scheduler;然后再执行一次 engine step。这里的关键是:请求不是一来就立刻 forward,而是先进入 scheduler,由 scheduler 统一决定本轮 step 该处理哪些请求、每个请求处理多少 token。- 会先进行
完成
EngineCoreProc._process_input_queue()后接着进行EngineCoreProc._process_engine_step()- 跳转至
EngineCore.step() - 执行
scheduler.schedule() - 然后会由
model_executor.execute_model(...)完成本次 step 模型推理
这一步是真正的推理执行阶段。
scheduler.schedule()会根据当前所有 waiting/running requests、KV Cache 状态、token budget 等信息生成本轮的SchedulerOutput。随后model_executor.execute_model(...)根据 scheduler 给出的 batch 执行模型 forward。换句话说,scheduler 决定这一轮算什么,model executor 负责“真正把这一轮算出来。- 跳转至
EngineCoreProc._process_engine_step()的末尾会执行EngineCoreProc.output_queue.put_nowait(...),放入output_queue
模型执行结束后,scheduler 会根据模型输出更新每个请求的状态,例如生成了哪些 token、哪些请求已经 finished、哪些请求仍然需要继续 decode。随后这些结果会被包装成 EngineCoreOutputs,放入 output_queue,等待输出线程发回主进程。
结果回收
EngineCoreProc.process_output_sockets(...)
|--- EngineCoreProc.output_queue.get()
|--- socket.send_multipart(...)
SyncMPClient.process_outputs_socket(...)
|--- output_socket.recv_multipart(...)
|--- deserialize EngineCoreOutputs
|--- SyncMPClient.outputs_queue.put_nowait(outputs)
*********************
LLM._run_engine(...)
|--- while LLMEngine.has_unfinished_requests():
|--- LLMEngine.step()
|--- LLMEngine.engine_core.get_output()
| |--- SyncMPClient.get_output()
| |--- SyncMPClient.outputs_queue.get()
|
|--- LLMEngine.output_processor.process_outputs(...)
| |--- detokenization
| |--- stop condition check
| |--- finished request update
| |--- construct RequestOutput
|
|--- return list[RequestOutput]
LLM._run_engine(...)
|--- collect outputs
|--- sort by request_id
|--- return final outputs- 在
EngineCoreProc.process_output_sockets()线程时,当一次推理 step 完成之后会触发output = self.output_queue.get()(没完成时会阻塞)
process_output_sockets() 是另一个专门负责 IO 的线程。它不断从 output_queue 中取出 EngineCoreOutputs。如果当前没有任何 step 输出,它就阻塞在 output_queue.get() 上,不会占用主循环执行模型的路径。
- 这个线程通过
socket.send_multipart(...)将其送回主进程
这一步完成从 EngineCoreProc 到主进程的反向通信。也就是说,请求输入是主进程通过 input_socket 发给 EngineCoreProc,而推理结果则由 EngineCoreProc 通过 output socket 发回主进程。
- 在主进程上,有一个
process_outputs_socket()线程5专门处理从EngineCoreProc返回的请求输出。它会从 socket 读取数据,并放入局部变量outputs_queue中:outputs_queue.put_nowait(outputs)
主进程侧也有一个输出处理线程。它负责监听 EngineCoreProc 发回来的结果,反序列化成 EngineCoreOutputs,然后放入 SyncMPClient.outputs_queue。注意这里仍然只是搬运结果,还没有把 token 转换成最终用户看到的 RequestOutput。
- 由第一步
LLM._run_engine(...)在完成请求发送且请求尚未全部完成时,会循环执行LLMEngine.step()。在这个函数中,会执行LLMEngine.engine_core.get_output()。这里是由SyncMPClient.get_output()执行:
outputs = self.outputs_queue.get():同样也是阻塞执行。每一次从EngineCoreProc完成输出写回时,这里就会成功读取到数据,然后继续处理
这一步是主进程重新接管输出处理。LLMEngine.step() 会从 engine_core.get_output() 中拿到 EngineCoreOutputs,然后交给 output_processor.process_outputs(...)。这个过程会完成 detokenization、stop condition 检查、finished 状态更新以及最终 RequestOutput 的构造。
- 当所有请求全部完成处理时,由
LLM._run_engine(...)收集并排序输出,最终统一返回。
LLM._run_engine(...) 会持续循环,直到 LLMEngine.has_unfinished_requests() 返回 false。由于不同请求可能完成时间不同,最后还会根据 request_id 对输出重新排序,保证返回结果的顺序和用户输入顺序一致。至此,一次离线推理流程才完整结束。