Chunked Prefill
2 min
Chunked Prefill
参考论文:SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
NOTEChunked Prefill 通过将原本规模为 的 Causal Attention 计算重排为若干较小的分块计算,从而降低 Prefill 阶段的峰值显存占用,以及使得调度单元变得更加细粒度。
下图展示了 Chunked Prefill 的主要流程。Chunked Prefill 将原本一次性处理完整序列的 Prefill 过程拆分为多个按顺序执行的分块计算。设 Chunk size 为 ,则对于长度为 的输入序列,会被划分为 个 chunk 依次处理。
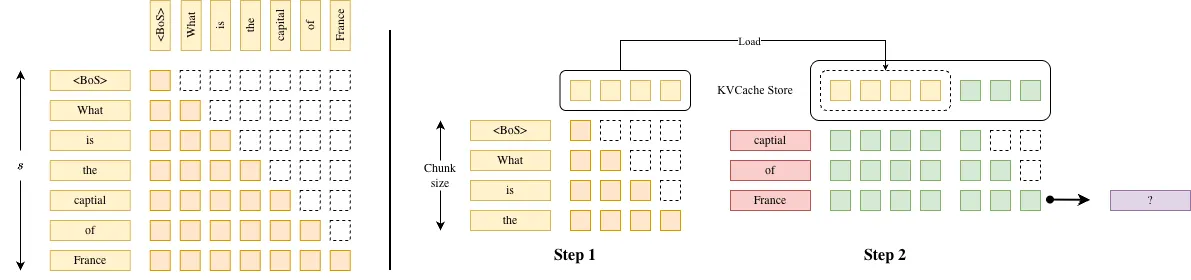
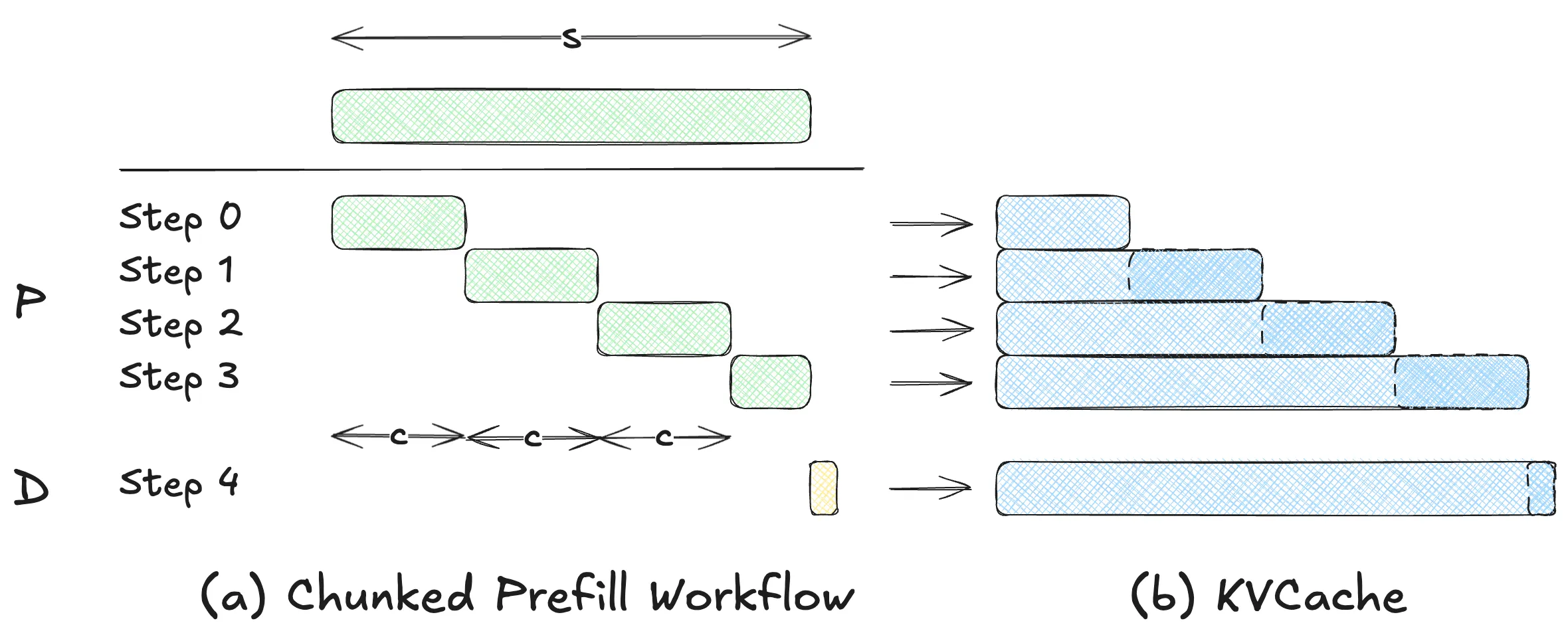
在每一次分块计算中,系统会:
- 选取当前 chunk 中的至多 个 token;
- 计算这些 token 的 表示,并将新生成的 写入 KV Cache;
- 将当前 chunk 的 与已累计的历史 (包括此前所有 chunk 的 token)进行因果 Attention 计算;
- 若该 chunk 为最后一段,则完成整个 Prefill 阶段,并进入后续 Decode 阶段。
需要注意的是 KVCache 总量并没有变少,但是中间每一步参与计算的 和 Attention 中间矩阵变小了。
应用场景
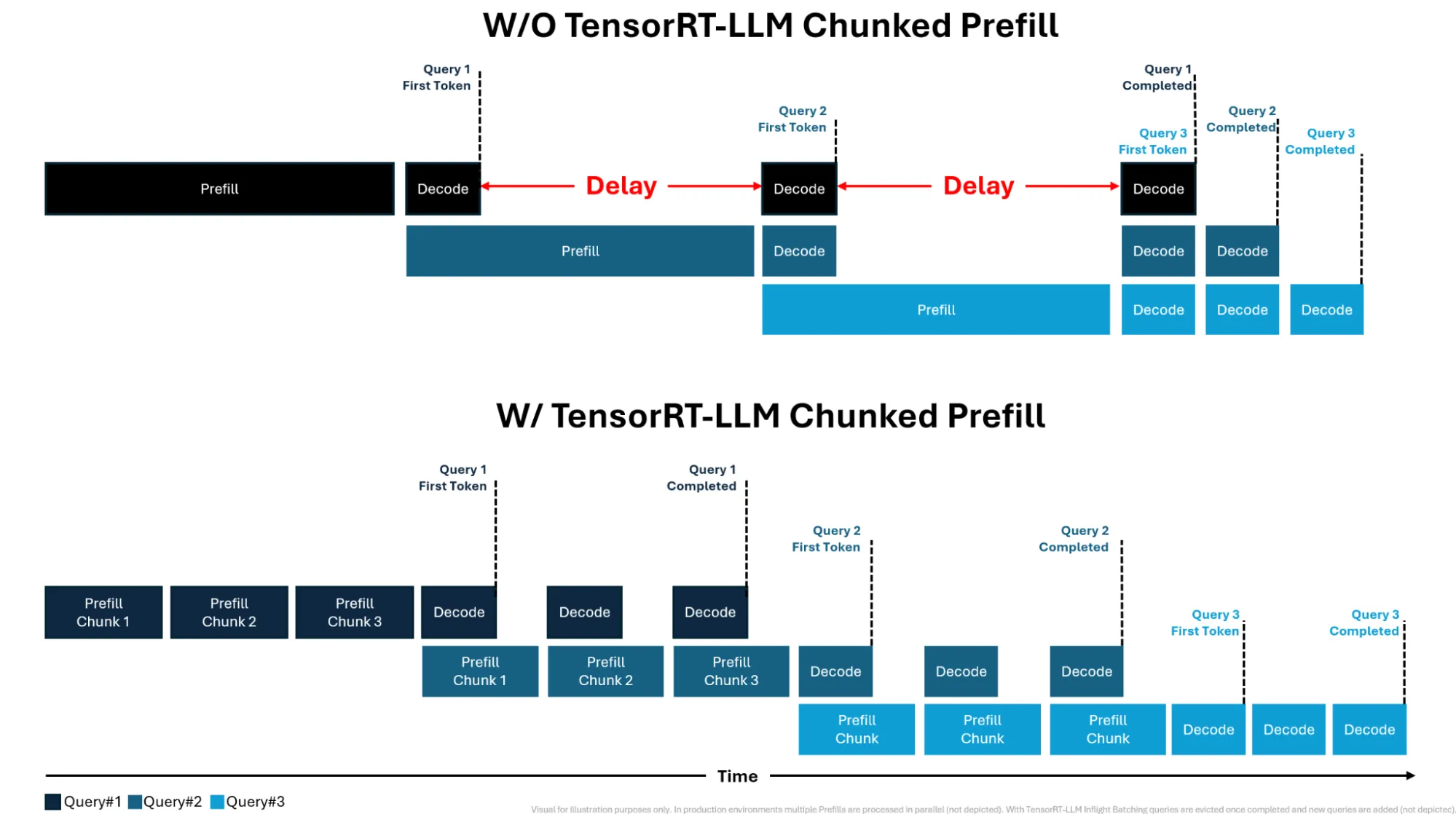
- 适配超长 Prompt,解决输入序列过长导致 GPU 资源不足的问题。在 Chunked Prefill 之后,大约可以降到原来的 .
- 调度单元变得更加细粒度,减少 Pipeline 以及调度产生的 bubble