本文介绍 FlashAttention 的核心思想,并推导其关键公式,说明其如何通过分块计算与在线 softmax 更新,在不显式构造 N×N attention 矩阵的情况下减少显存访问与内存开销,从而提高 GPU 计算效率。

Naive Attention
Standard Attention 可以建模为: 
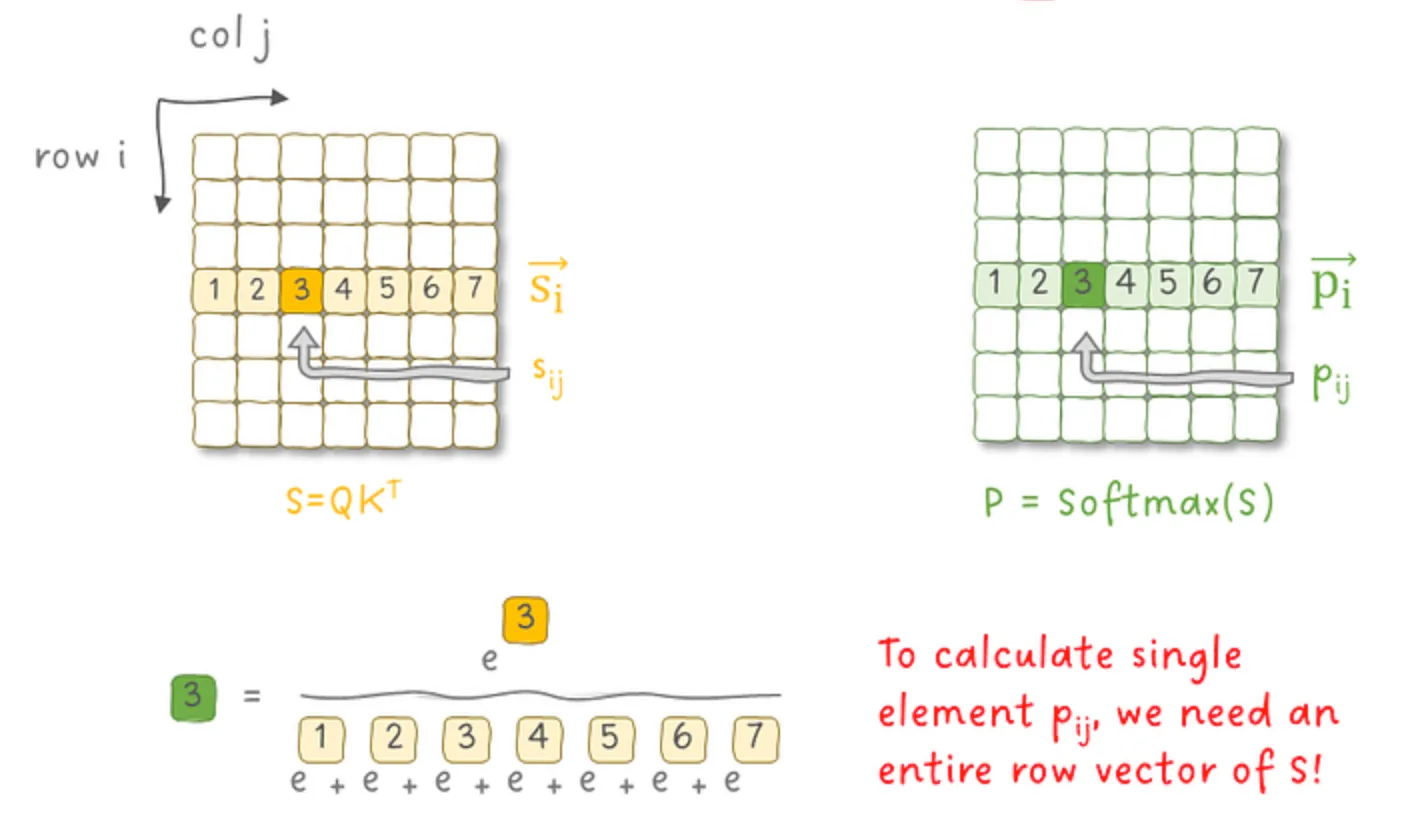
其中 (Safe) softmax 函数定义如下. 对于一个 vector x∈Rd,为了避免指数爆炸,定义:
m(x):=imaxxi,softmax(x):=∑j=1dexj−m(x)[…exi−m(x)…]∈Rd上图左侧表示 Algorithm 0 的流程。可以看到这会导致中间结果的 materialization:需要显式构建大小为 N×N 的矩阵 S 和 P,并将其写入和再次从内存中读取以完成后续计算。这会产生大量的 HBM 访问开销。
一个自然的优化思路是将上述三个步骤 融合为一个 kernel(Fused Kernel),使得每个元素在加载后立即参与后续计算,从而避免中间矩阵的物化。然而,这种融合会面临两个主要挑战:
- Softmax 的归一化依赖:如下图所示,softmax 的计算需要知道该行(或列)所有元素的归一化因子(即分母部分)以及向量中所有元素的最大值 m(x),因此在未遍历完整个向量之前无法得到最终结果。这使得 GEMM 操作和 softmax 操作没有办法 fuse.
- 训练阶段的反向传播需求:在训练过程中,需要保存 softmax 的中间结果(例如概率矩阵 P),以便在 backward pass 中计算梯度。
FlashAttention v1 Overview

Tiling
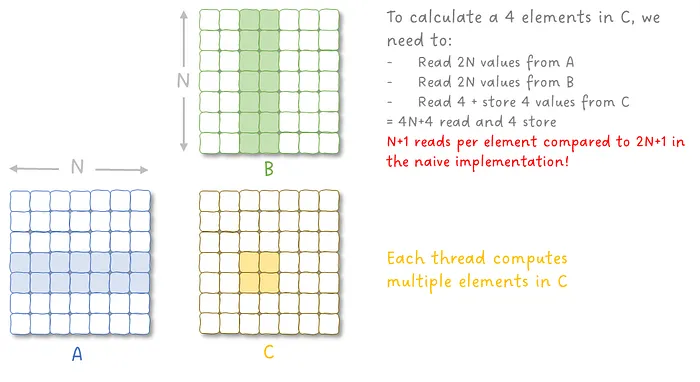
对于矩阵乘法(GEMM)的优化,一个核心思想是 Tiling(分块计算)。其基本动机是减少对慢速内存(如 HBM/DRAM)的访问次数,使数据在片上高速存储(如 cache / shared memory)中被尽可能多次复用。
考虑计算
C=AB⊤,A,B∈RN×d,C∈RN×N.为了提高数据复用率,我们将矩阵 A 和 B 按 行维度切分成多个小块(tiles)。设 tile 的大小分别为 dA 和 dB,则:
A=A1⋮ATA,Ai∈RdA×d,TA=⌈dAN⌉ B=B1⋮BTB,Bj∈RdB×d,TB=⌈dBN⌉对应地,输出矩阵 C 也被划分为若干子块:
Cij∈RdA×dB,Cij=AiBj⊤.因此整个矩阵乘法可以通过如下分块计算完成:
- For 1≤i≤TA
- Load Ai 到片上高速内存
- For 1≤j≤TB
- Load Bj
- 计算 Cij=AiBj⊤
- 将结果写回对应的 Cij
最终返回矩阵 C。
这种 分块计算(tiling) 的关键优势在于:
- 每个 tile(如 Ai 或 Bj)只需从全局内存读取一次
- 在片上内存中可以被多次复用
- 显著减少 HBM 访问带宽压力
因此,现代 GPU 的高性能 GEMM 实现(如 CUDA kernel、TensorCore kernel)都会采用类似的 tile-based 计算策略 来提高计算效率。
Tiling in FlashAttention
在 FlashAttention 中,因为需要对 Q.K 以及 f(Q.K).V 做 GEMM 运算,因此将 Q, K 和 V 矩阵都进行分块,切分维度在 sequence dimension 上,即分别将 Q 和 {K,V} 切分成 RBr×d 和 RBc×d 的块。
在计算中,outer loop 是 K 和 V 矩阵(对应上一小节的 B 矩阵,按列切分);inner loop 是 Q 以及形状相同的 O 矩阵。这可以使得 K 和 V 的复用最大化。在每个 tile 内都进行了大小为
RBr×d×Rd×Bc→RBr×Bc的计算,后续第 9-13 行是每个 tile 的计算内容。

Online Softmax
增量 softmax
首先,我们希望解决 Softmax 的数据依赖问题。理想情况下,当逐步访问向量 x∈Rd 的元素时,我们能够 在线(online)更新 softmax 的统计量,从而在一次扫描中完成 softmax 的计算,而不需要多次遍历整个向量。
在最朴素的实现中,softmax 通常需要 三次遍历向量 x,每次都需要从内存读取 d 个元素,总的内存访问量约为 3d:
- 遍历 x,以计算出 x 的最大值 m(x)
- 遍历 x,以得到 softmax 运算中的分母部分(归一化因子)
- 遍历 x,逐元素得到其分子部分
而实际上 softmax 可以采用增量的方式来减少一次遍历,这是因为 softmax 运算中的分母部分可以跟随 x 最大值的更新而更新。
假设遍历到第 j 个元素,
- 更新所有元素的最大值:得到 mj−1(x)=max(x1,…,xj−1),因此 mj(x):=max(mj−1(x),xj),其满足 mj(x)≥mj−1(x)
- 放缩:更新归一化因子,即 softmax 运算中的分母部分:得到 dj−1(x)=∑t=1j−1et−mj−1(x). 因此 dj(x):=dj−1×emj−1(x)−mj(x)+exj−mj(x)
中间推导过程:
dj(x)=t=1∑jext−mj(x)=dj−1(x)t=1∑j−1ext−mj−1(x)⋅emj−1(x)−mj(x)+exj−mj(x)最后再遍历一次向量 x,逐元素计算最终的 softmax 输出:
softmax(x):=dn(x)[…exi−md(x)…]∈Rd这样 softmax 的计算只需要 两次遍历向量 x,总的内存访问量约为 2d。
更重要的是,通过维护运行中的最大值 mj(x) 和归一化因子 dj(x),softmax 的统计量可以在遍历过程中 逐步更新(online update),从而避免了必须先访问所有元素才能开始计算 softmax 的问题。

合并两个向量的 Softmax 统计量
在上一小节中,我们介绍了如何在遍历向量 x′=[x1…xj−1] 时,通过新元素 xj 对 softmax 的统计量进行增量更新,从而得到新的归一化因子。
在这一个小节,我们运用同样的思想 merge 两个向量 x(1)∈RB 和 x(2)∈RB 的 softmax 结果,从而得到拼接向量 x=[x(1)x(2)]∈R2B 的 softmax 拼接结果。 对于每个向量,我们保存其最大值 m(1)=maxi{xi(1)} 和 m(2)=maxi{xi(2)} 和分母(即归一化因子)的结果:l(1)=∑iexi(1)−m(1) 和 l(2)=∑iexi(2)−m(2),接下来的操作基于这 4 个 state (m(1),m(2),l(1),l(2)) 进行。
定义原来两个向量 softmax 计算中的分子向量 f(1)=[…exi(1)−m(1)…] 和 f(2)=[…exi(2)−m(2)…] ,这意味着:
softmax(x(i))=l(i)f(i)∈RB,i∈{1,2}我们希望得到的结果:(其中 f=f(f(1),f(2)) 和 l=l(l(1),l(2)) 需要求解)
softmax(x)=l(x)f(x)∈R2B,f(x)∈R2B,l(x)∈R首先更新 x 的最大值:m(x)=max(m(1),m(2)).
接下来是分别对 Softmax 的分母和分子部分进行放缩(借助于我们所存储的指数计算求和结果的 l 值):
Softmax 的分母部分:
l(x)=l(1)×em(1)−m(x)+l(2)×em(2)−m(x)Softmax 的分子部分因为 x 的最大值发生了变化同样也需要进行放缩(逐元素操作):
f(x)=[f(1)×em(1)−m(x)f(2)×em(2)−m(x)]∈R2B这使得我们能够先对矩阵的一个 chunk(或 tile) 进行局部 softmax 计算。更准确地说,我们计算的是 softmax 的 统计量(最大值和归一化因子)。随后通过重新缩放这些统计量,可以将不同 chunk 的结果合并,从而得到整个向量的正确 softmax 归一化结果。
这种性质使得 softmax 可以 按块(tile-wise)计算并逐步合并,从而与 attention 的分块计算方式相结合,使得 QKT、softmax 和 PV 可以在同一个 kernel 中完成,而无需显式物化中间的 N×N attention 矩阵。每个 tile 在加载到共享内存后,可以完成该 tile 对输出 O 的 部分贡献的计算,并将结果累积到当前的输出中。
Online Softmax in FlashAttention
现在我们放在 Attention 情况下,思想也是完全相同:更新最大值,再对分子分母进行放缩。

在进行矩阵分块计算的背景下,假设 outer loop index = j,inner loop index = i,且 {Qi,Oi}∈Br×d,{Kj,Vj}∈d×Bc,我们希望对于:
- 之前计算结果 Oi∈Br×d 的 softmax 计算,可以表示为 Oi=linumerator,wherenumerator=Oili 且 numerator 和 mi 相关(当 mi 改变时分子也要进行缩放),以及是 softmax 运算和 V 矩阵计算的结果
- 以及当前 tile 的局部 softmax 计算,可以表示为 softmax~ij(m~ij)=l~ijP~ij∈RBr×Bc 进行合并。
首先是 tile 内部的 softmax 计算。第 10 行是 tile 内部的 state 计算:m~ij 表示每一行的最大值,P~ij 表示每一行的 softmax 分子,l~ij 表示每一行的 softmax 分母。
m~ij=rowmax(Sij)∈RBr,P~ij=exp(Sij−m~ij)∈RBr×Bc,l~ij=rowsum(P~ij)∈RBr局部的 softmax 由以下计算得到,且只与 m~ij state 有关(因此当它被更新的时候需要对局部 softmax 也进行更新):
softmax~ij(m~ij)=l~ijP~ij∈RBr×Bc然后将之前的计算结果与本次计算结果进行合并:第 11 行是局部 state 与 HBM 中缓存的全局 state 的更新:
minew=max(mi,m~ij)∈RBr,linew=li×emi−minew+l~ij×em~ij−minew∈RBr第 12 行最为关键:它将“旧的累计结果”与“当前 tile 的新贡献”在统一数值尺度下合并,并完成归一化更新。
(1) 分子部分 1:当前 tile 的新贡献(未归一化的 numerator 增量)
先计算
O~ij=P~ijVj∈RBr×d.由于本轮更新后的 running max 变为 minew,需要对每一行做指数重缩放:
Δi=diag(em~ij−minew)O~ij∈RBr×d.(2) 分子部分 2:旧的累计结果对应的贡献(在新尺度下重缩放)
将先前累计的输出 Oi(它对应旧尺度 mi,li)恢复为未归一化的 numerator,并将指数尺度从 mi 重缩放到新的 minew:
Φi=diag(liemi−minew)Oi∈RBr×d.(3) 归一化因子即为 linew.
(4) 合并并归一化,得到新的输出
Oinew=new denominatorold numerator+new numerator=diag(linew)−1(Φi+Δi)∈RBr×d.这与论文中的写法等价:
Oinew=diag(linew)−1(diag(li)emi−minewOi+em~ij−minewP~ijVj),其中 em~ij−minew 表示对矩阵按行 broadcast 的逐行缩放。
参数初始化:O 和 l 采用零初始化而 m 初始化为 −∞. 这意味这对于第一个 iteration,即为标准的 softmax.
参考资料