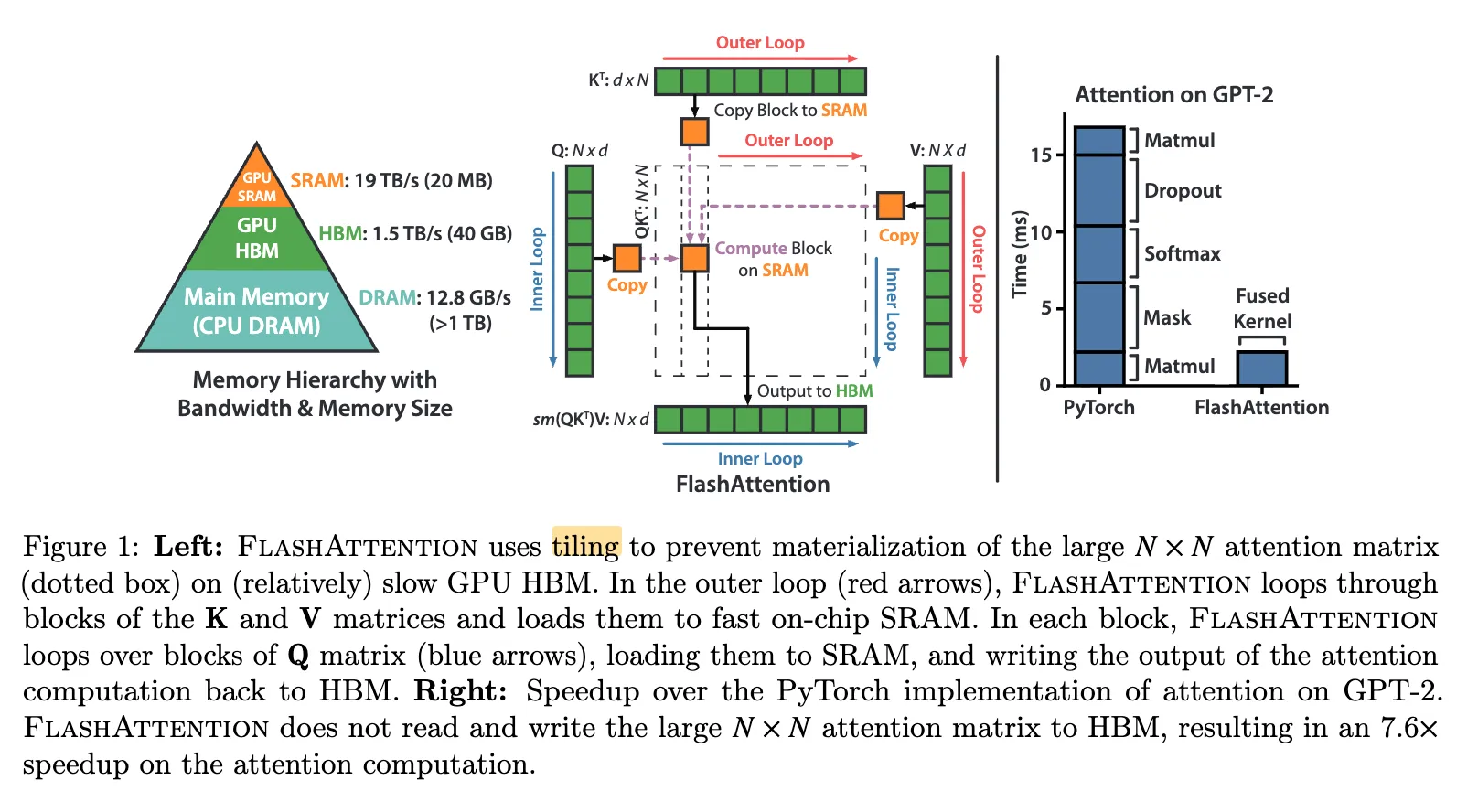
FlashAttention 1 相较于标准 Attention 计算其更快的主要原因在于它是 IO-aware 的。其将注意力计算划分为能够放入 GPU 片上 SRAM(共享内存)的小块(tile),并通过 online softmax 逐步计算 softmax。中间结果始终保存在更快的 SRAM 中,而不会被写回 HBM。每个块的最终输出只在计算完成后写回一次 HBM。HBM 的数据访问量从原来的 O(n2) 降低到 O(n⋅d), 其中 d 是每个 head 的维度,达到了读取输入和写入输出所需的理论最小值。在 NVIDIA A100 上,对于长序列,FlashAttention 相比标准注意力通常可以获得 2–4 倍的加速。
参考论文:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness

Naive Attention 问题分析
Standard Attention 可以建模为: 
其中 (Safe) softmax 函数定义如下. 对于一个 vector x∈Rd,为了避免指数爆炸,定义:
m(x):=imaxxi,softmax(x):=∑j=1dexj−m(x)[…exi−m(x)…]∈Rd下面展示计算 Attention Block 的算法流程。可以看到:
- 标准 Attention 需要显式构造中间矩阵(如 S=QK⊤ 和 P=softmax(S)),其规模为 N×N
- 这些中间结果需要在 HBM 中反复写入和读取,带来大量的数据搬运开销
- 因此,Attention 的执行往往受限于内存带宽(memory bandwidth),而非计算能力
 FlashAttentionAlgo1
FlashAttentionAlgo1一个自然的优化思路是将上述三个步骤 融合为一个 kernel(Fused Kernel),使得每个元素在加载后立即参与后续计算,从而避免中间矩阵的物化。然而,这种融合会面临两个主要挑战:
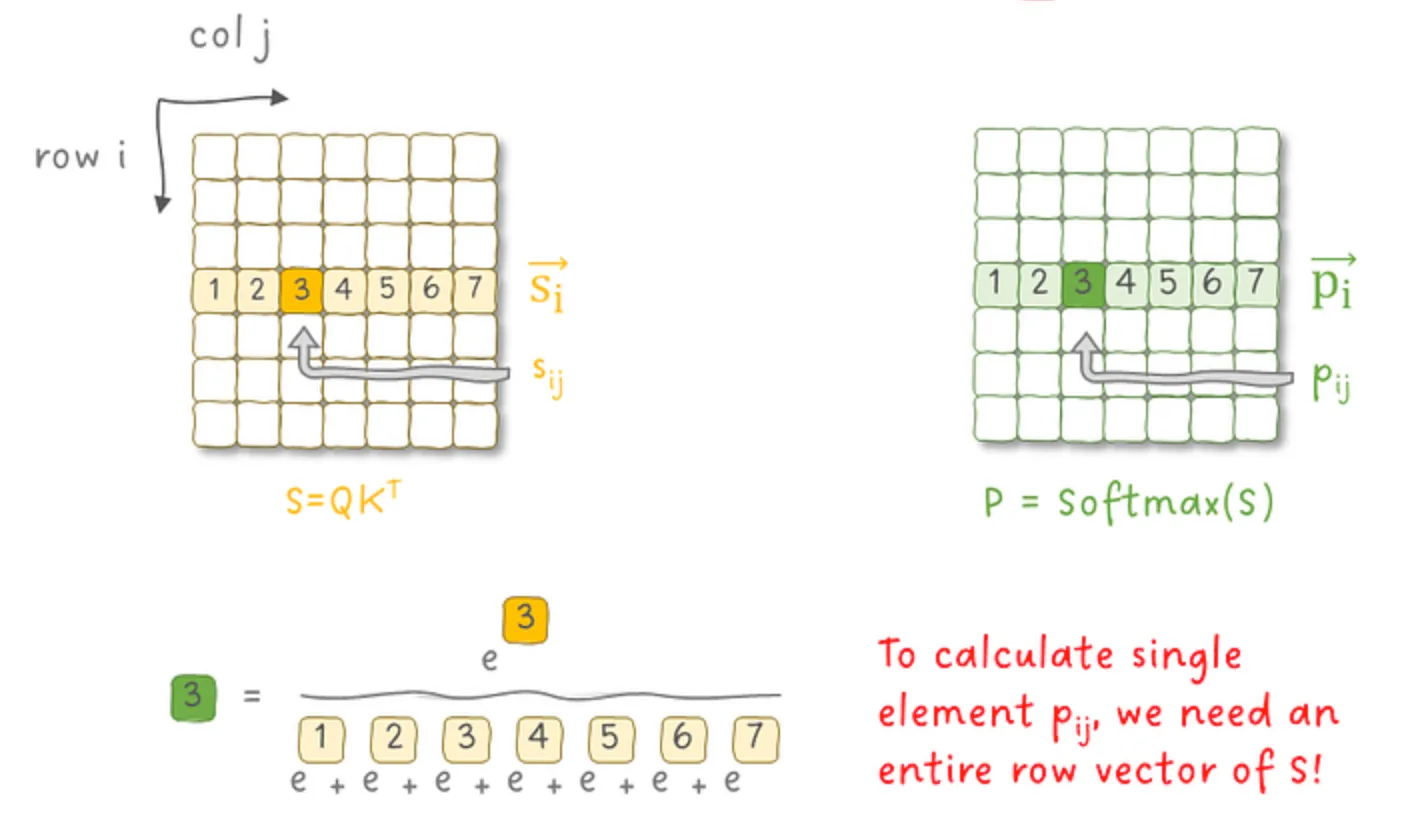
- Softmax 的归一化依赖:如下图所示,
- 为了计算 softmax 需要知道
- 向量中所有元素的最大值 m(x)
- 该行(或列)所有元素的归一化因子(即分母部分)
- 因此在未遍历完整个向量之前无法得到最终结果。
- 这使得 GEMM 操作和 softmax 操作没有办法融合。
- 训练阶段的反向传播需求:在训练过程中,需要保存 softmax 的中间结果(例如概率矩阵 P),以便在 backward pass 中计算梯度。
FlashAttention v1 Overview

背景:Tiling
对于矩阵乘法(GEMM)的优化,一个核心思想是 Tiling(分块计算)。其基本动机是减少对慢速内存(如 HBM/DRAM)的访问次数,使数据在片上高速存储(如 cache / shared memory)中被尽可能多次复用。
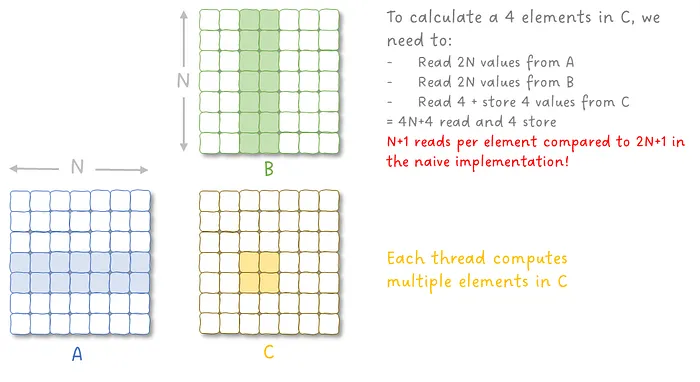
考虑计算
C=AB⊤,A,B∈RN×d,C∈RN×N.为了提高数据复用率,我们将矩阵 A 和 B 按 行维度切分成多个小块(tiles)。设 tile 的大小分别为 dA 和 dB,则:
A=A1⋮ATA,Ai∈RdA×d,TA=⌈dAN⌉ B=B1⋮BTB,Bj∈RdB×d,TB=⌈dBN⌉对应地,输出矩阵 C 也被划分为若干子块:
Cij∈RdA×dB,Cij=AiBj⊤.因此整个矩阵乘法可以通过如下分块计算完成:
- For 1≤i≤TA
- Load Ai 到片上高速内存
- For 1≤j≤TB
- Load Bj
- 计算 Cij=AiBj⊤
- 将结果写回对应的 Cij
最终返回矩阵 C。
这种 分块计算(tiling) 的关键优势在于:
- 每个 tile(如 Ai 或 Bj)只需从全局内存读取一次
- 在片上内存中可以被多次复用
- 显著减少 HBM 访问带宽压力
因此,现代 GPU 的高性能 GEMM 实现(如 CUDA kernel、TensorCore kernel)都会采用类似的 tile-based 计算策略 来提高计算效率。
Tiling in FlashAttention
在 FlashAttention 中,因为需要对 Q.K 以及 f(Q.K).V 做 GEMM 运算,因此将 Q, K 和 V 矩阵都进行分块
- 切分维度在 sequence dimension 上,即分别将 Q 和 {K,V} 切分成形状为 RBr×d 和 RBc×d 的块。
- 因此 Q 和 {K,V} 被切分成 Tr=⌈BrN⌉ 和 Tc=⌈BcN⌉ 数量的小块。
在计算中,
- Outer loop 是 K 和 V 矩阵(对应上一小节的 B 矩阵,按列切分)
- Inner loop 是 Q 以及形状相同的 O 矩阵
- 这么设计 Outer-Inner loop 是为了让“大且昂贵”的数据 (K,V) 尽可能少地从 HBM 读取
- 在每个 tile 内都进行了大小为
RBr×d×Rd×Bc→RBr×Bc的计算,后续第 9-13 行是每个 tile 的计算内容。

Online Softmax
Online Softmax 算法推导
关于 Online Softmax 算法推导,请见 Online Softmax 推导 文章。
Online Softmax in FlashAttention
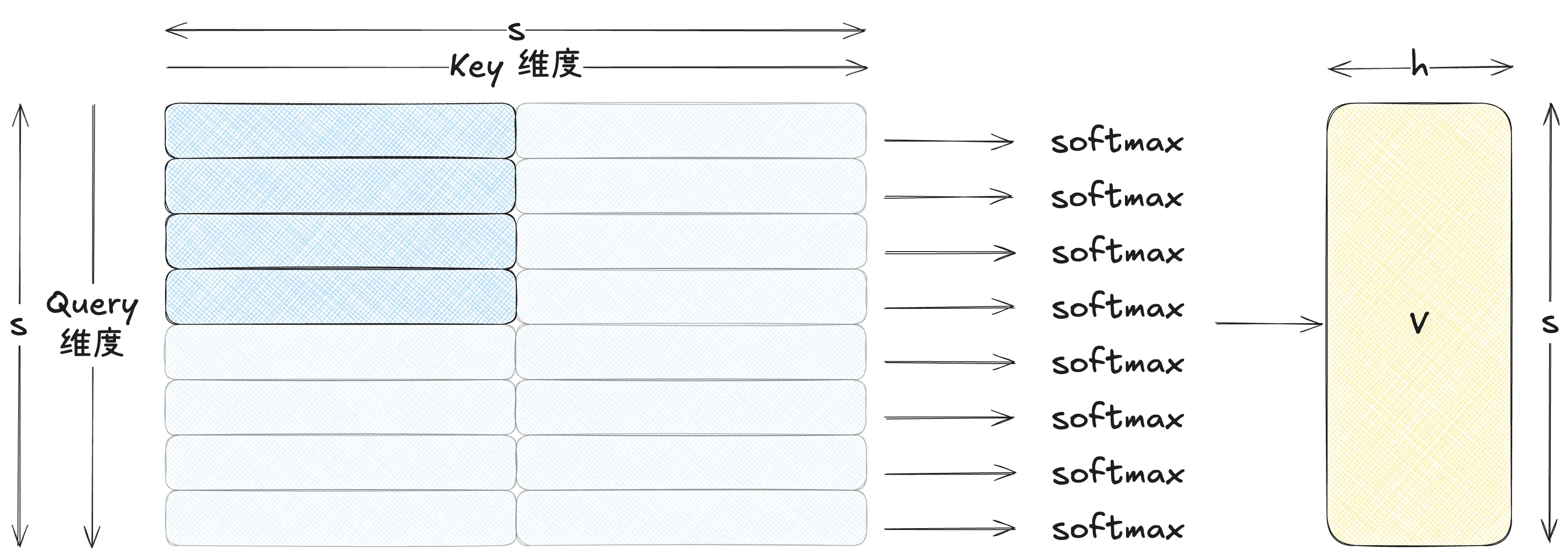
现在我们放在 Attention 情况下,思想也是完全相同:更新最大值,再对分子分母进行放缩。在 Attention 计算中,
- 每一行,对应一个 query 是一个独立 softmax
- 每个 query 在扫描 K 的过程中做 online softmax
- 可以理解为同时对于多行,每一行是对应一行独立的 softmax,在扫描 K 维度的过程中做 online softmax,不同行之间相互独立、互不干涉
下图是 Flash Attention v1 原文的求解算法:
- 第 10 行介绍了每一行需要计算的局部状态,主要包括了 online softmax 的元素最大值 m~ij 和归一化因子 l~ij,与此同时还需要记录每一个元素的分子部分 P~ij,用于与 Vj 相乘。
- 第 11 行介绍了每一个 tilde 对于局部状态的更新计算公式
- 第 12 行介绍了每一个 tilde 对于输出矩阵的更新计算公式
具体而言,可以用下图总结(图中各个序号对应了下一章节推导的步骤):
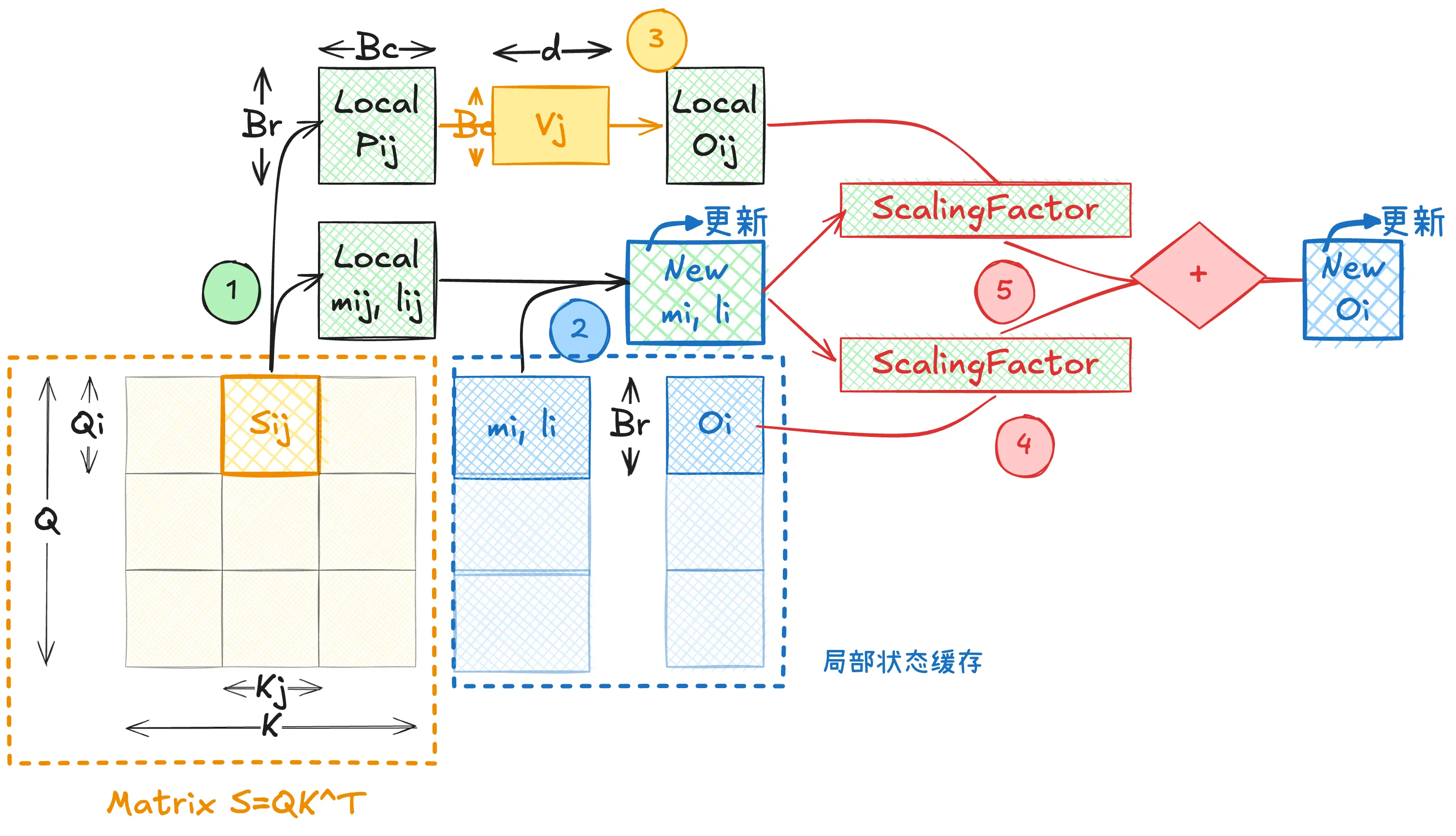
核心局部状态计算和更新公式推导
在进行矩阵分块计算的背景下,设 outer loop index 为 j,inner loop index 为 i。输出矩阵记为 O。对第 i 个 query block,有:
Qi∈RBr×d,Kj,Vj∈RBc×d.对应的 attention score 为:
Sij=QiKjT∈RBr×Bc.对第 i 个 block,我们维护 row-wise 的 softmax 状态:
mi∈RBr,li∈RBr,Oi∈RBr×d.其中:
- mi:当前已处理部分的 row-wise 最大值
- li:对应的 归一化因子
- Oi:已经归一化后的输出
对应的未归一化 numerator定义为:
Ni=diag(li)Oi∈RBr×d.对于每个 Tile:
1. Tile 内部 softmax。首先在当前 tile 上计算局部状态:
⎩⎨⎧m~ijP~ijl~ij=rowmax(Sij)∈RBr,=exp(Sij−m~ij)∈RBr×Bc,=rowsum(P~ij)∈RBr.对应的局部 softmax(仅用于推导,不显式计算)为:
softmax~ij=l~ijP~ij.
2. 更新 running max 和 normalizer
{minewlinew=max(mi,m~ij)∈RBr,=li⊙emi−minew+l~ij⊙em~ij−minew∈RBr.其中 ⊙ 表示逐元素乘法(row-wise)。
3. 当前 tile 的新贡献(numerator)
计算当前 tile 的未归一化输出:
O~ij=P~ijVj∈RBr×d.4. 历史结果的重缩放
原有 numerator 为:
Ni=diag(li)Oi.5. 合并 3+4 并归一化
⎩⎨⎧Δi=diag(em~ij−minew)O~ij.Φi=diag(emi−minew)Ni=diag(liemi−minew)Oi.Oinew=diag(linew)−1(Φi+Δi)∈RBr×d.等价写法为:
Oinew=diag(linew)−1(diag(li)emi−minewOi+em~ij−minewP~ijVj),总结
在 Flash Attention V1 实现中,维护局部变量 (mi,li,Oi),对于每个 tilde 进行计算时将其进行更新。
对于局部变量计算有(第一步):
⎩⎨⎧m~ijP~ijl~ijO~ij=rowmax(Sij)∈RBr,=exp(Sij−m~ij)∈RBr×Bc,=rowsum(P~ij)∈RBr.=P~ijVj∈RBr×d.状态更新 (mi,li)→(minew,linew) 式子(第二步):
{minewlinew=max(mi,m~ij)∈RBr,=li⊙emi−minew+l~ij⊙em~ij−minew∈RBr.最终更新输出矩阵 Oi→Oinew(第三-五步):
⎩⎨⎧Ni=diag(li)Oi.Φi=diag(emi−minew)Ni=diag(liemi−minew)Oi.Δi=diag(em~ij−minew)O~ij.Oinew=diag(linew)−1(Φi+Δi)∈RBr×d.参考资料