本文将会介绍 LLM 的核心部件 Attention.
参考论文:Attention Is All You Need
引入
假设输入是一段 token 序列:
w1:n=(w1,w2,…,wn).在现代语言模型中,原始文本先经过 tokenizer,被切分并映射为一串 token ids:
texttokenizer(t1,t2,…,tn),其中每个 ti∈{0,1,…,∣V∣−1} 表示词表 V 中的一个 token id。
接下来,模型会通过一个 embedding table 将每个 token id 映射到一个 d 维向量空间中。记 embedding table 为:
E=−E1−−E2−⋮−E∣V∣−∈R∣V∣×d,那么第 i 个 token 的 embedding 可以直接理解为从 embedding table 中取出第 ti 行:xi=E[ti]∈Rd.
对于整个序列,我们可以得到:
X=x1=E[t1]x2=E[t2]⋮xn=E[tn]∈Rn×d.这里得到的是每个 token 的 non-contextual representation:
xi∈Rd.所谓 non-contextual,是指此时 xi 只由 token id 本身决定,不依赖它出现在什么句子、什么上下文中。也就是说,只要 token id 相同,从 embedding table 中查到的初始向量就是相同的。
但语言理解真正困难的地方在于:一个 token 的含义往往不是孤立决定的,而是由它所在的上下文共同决定的。因此,在得到初始 embedding 之后,我们还需要通过一个序列建模结构,例如 RNN 或 Transformer,让不同位置的 token 之间发生信息交互。
经过上下文建模之后,第 i 个位置会得到新的表示:
hi∈Rd.这里的 hi 就是 contextual representation。它不再只由当前 token 本身决定,而是由当前 token 以及它能够看到的上下文共同决定。
在自回归语言模型中,由于预测当前位置时不能看到未来信息,因此 hi 通常只能依赖当前位置及其之前的 tokens:
hi=f(x1,x2,…,xi).这里我们不展开介绍 RNN 是如何实现的,通常情况下每个 token 的 contextual representations 是根据以下方式得到的:
hi=RNN(xi,hi−1),RNN Sentence Encoding:平均池化
在 RNN 最为流行的时代,为了通过一段文字得到二分类评价(比如评价一个评论是正面还是负面的)往往采取 Sentence Encoding:例如,可以通过 mean-pooling 得到句子表示:
hsentence=n1i=1∑nhi这种方法的核心问题在于:它本质上是在对所有 token 的表示做平均。这意味着每个 token 都被赋予相同权重,模型无法区分哪些词更重要,也无法动态关注与当前任务最相关的信息。与此同时,mean pooling 本身也会压缩序列结构,使得词序信息和长距离依赖容易被弱化。 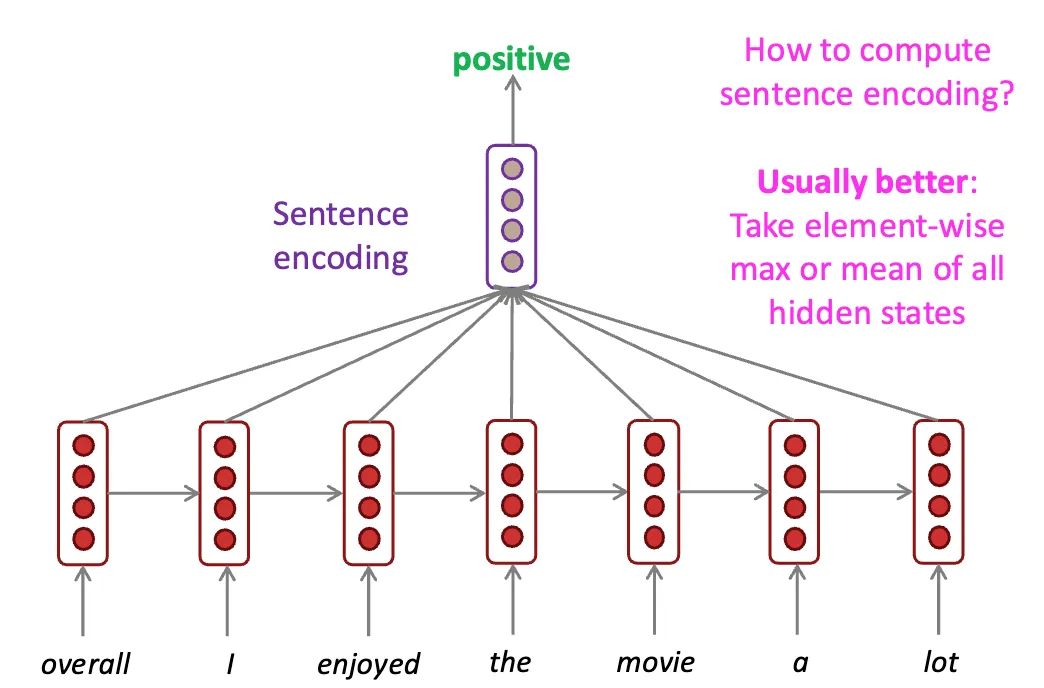
Attention:对所有“词向量”的加权平均
基于上述 mean-pooling 的思想,Attention 可以看作一种 数据依赖的加权池化:不同的上下文 token 会被分配不同的重要性权重,而不是均匀平均。
权重计算:Lookup Table 的思想
Attention 本质上可以理解为一种加权平均(weighted aggregation)。而当这些权重能够根据输入内容动态学习时,这种机制就会变得非常强大。
为了理解 Attention,可以先从传统的 查找表(lookup table) 出发。无论是编程语言中的字典(dictionary),还是更底层的哈希表,本质上都在维护一种 key->value 的映射关系。
如下图所示:
- 我们拥有一组 key,每个 key 对应一个 value
- 当给定一个 query 时,系统会找到与之匹配的 key
- 随后返回该 key 对应的 value
传统 lookup table 的特点在于:query 最终只会匹配到一个 key,因此本质上是一种 one-hot selection。用 α 表示这个过程,用公式可以表示为:
O=i∈Lookup Table Key∑αiVi,αi∈{0,1},i∑αi=1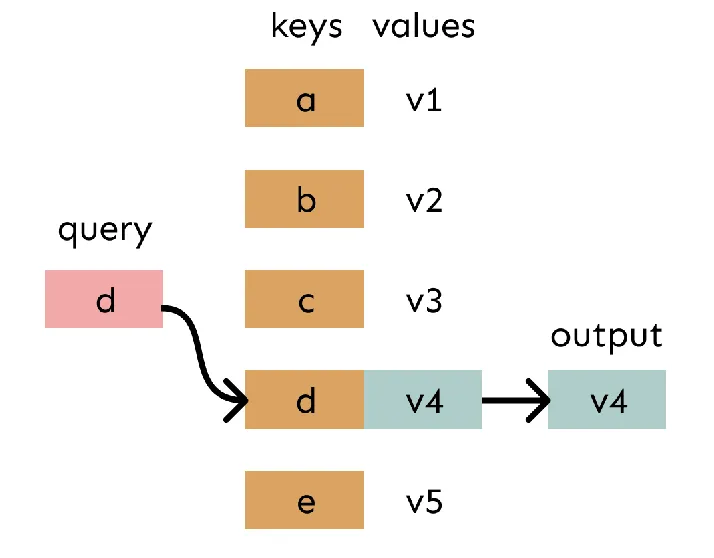
而在 Attention 中:
- query 会对所有 key 进行“匹配”,得到一组介于 0 和 1 之间的权重。 这个权重值由 query 和 key 的值决定。这一步意味着 α 不再是 one-hot selection.
- 每个 key 对应的 value 会乘以对应权重,然后进行加权求和
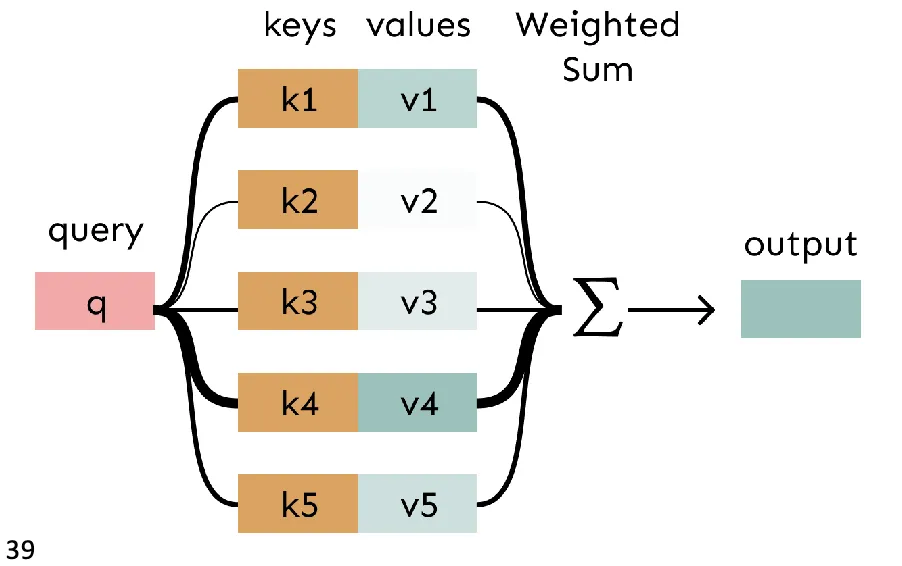
每个上下文 token 现在有两个向量需要表示:
- K 值:与 Query 进行点乘计算,以得到该 token 的权重值。K 决定了该不该关注这个 token
- V 值:表示该 token 实际提供给上下文聚合的信息内容
Attention 公式表达
考虑序列 x1:n 中的一个 token xi∈Rd×1。我们定义其对应的查询向量(query)为:
qi=Qxi,Q∈Rd×d注:这里为了方便数学推导,将单个 token 表示为列向量形式。在实际深度学习框架中,每个 tensor activation 的形状是 [b,s,d],因此每个 token 是行向量。
对于序列中的每一个 token xj∈{x1,…,xn},我们分别定义对应的键(key)和值(value)为:
kj=Kxj,vj=Vxj其中 K∈Rd×d,V∈Rd×d。
那么,对于序列中任意 token xi 的上下文表示(contextual representation) hi,也就是 attention 的输出,是对整个序列中 value 的加权线性组合:
hi=j=1∑nαijvj其中权重 αij 表示第 j 个 token 对 xi 的贡献强度(重要性)。
为了让模型能够在所有上下文 token 之间动态分配注意力,以及让输出尺度稳定,我们通常希望这些权重形成一个概率分布,这些权重的计算方式如下:
- 首先计算 query qi 与所有 key {k1,…,kn} 的相似度(affinity),通常使用点积 qiTkj
- 然后在 key 维度上做 Softmax 归一化
因此,对于序列中任意两个 token xi 和 xj,其注意力权重 αij 表示在计算 xi 的上下文表示时,第 j 个 token 对其贡献的强度,其计算方式为:
αij=[softmax(qiKT)]j=∑t=1nexp(qiTkt)exp(qiTkj)这里:
- 分子表示当前 query 与第 j 个 token 的匹配程度
- 分母则是在所有 token 上进行归一化,使得所有注意力权重之和为 1
进一步地,对于单个 query qi,我们可以得到其对应的完整注意力分布:
αi=(αi1,αi2,…,αin)它描述了当前 token 在理解自身时,会从整个上下文中的哪些 token“读取”多少信息。
可解释性(Interpretability)
注意力机制提供了一定程度的可解释性:
- 通过观察注意力分布,可以看到模型在关注哪些位置
- 可以“免费”获得(soft)对齐关系(alignment)
- 模型会自行学习这种对齐关系
注意力分布示例:
 图中的每一行表示一个 query 对整个输入序列的注意力分布,横轴表示 key/value 所对应的输入 token,颜色越深,表示注意力权重越高。这里展示的是一个机器翻译任务。可以看到,当模型生成法语中的 “il” 时,其注意力主要集中在英文中的 “he” 上
图中的每一行表示一个 query 对整个输入序列的注意力分布,横轴表示 key/value 所对应的输入 token,颜色越深,表示注意力权重越高。这里展示的是一个机器翻译任务。可以看到,当模型生成法语中的 “il” 时,其注意力主要集中在英文中的 “he” 上Self-Attention
在普通的 Attention 计算公式中,Q 与 (K,V) 的来源没有任何约束,它们可以来自不同的表示。
Attention:(Q,K,V)↦softmax(QKT)VSelf-Attention(自注意力) 是一种特殊情况,其中 Q,K,V 都来自同一个输入序列。给定输入序列表示 X:
Q=XWQ,K=XWK,V=XWV序列顺序问题 - 位置编码(Position Embedding)
自注意力本身不包含顺序信息,因此我们需要显式地编码序列中的位置信息,使 Attention 不仅能判断哪些 token 时相关的,还有基于它们的相对位置判断(例如“它、他、她”指代谁?)并将其融入到 Q,K 中。
对 WV 并不严格必要,因为 WVxi 本身是非上下文的。
将每个位置表示为一个向量:
∀i∈{1,...,n}:pi∈Rd设 xi 是 token wi 的 embedding,则带位置的表示通常为:
Embed(x,i)=xi+pi∈Rd也可以拼接(concatenate),但实践中通常采用相加(add)。
正弦位置编码(Sinusoidal Position Encoding)
使用不同频率的正弦和余弦函数来编码位置:
 sin_pepi=sin(i/100002j/d)cos(i/100002j/d)⋮sin(i/100002(d/2)/d)cos(i/100002(d/2)/d)
sin_pepi=sin(i/100002j/d)cos(i/100002j/d)⋮sin(i/100002(d/2)/d)cos(i/100002(d/2)/d)优点
- 周期性意味着模型更关注相对位置,而不是绝对位置
- 理论上可以外推到更长序列
缺点
可学习位置编码
核心思想:
∀i∈{1,...,n},pi作为可学习参数,构成矩阵:
p∈Rd×n每个 pi 是一列。
优点
缺点
现代位置编码 - RoPE
设 embedding 函数为:
f(x,i)核心思想
希望表示满足:
即:
⟨f(x,i),f(y,j)⟩=g(x,y,i−j)但传统的:
f(x,i)=xi+pi会引入 ⟨pi,y⟩, ⟨x,pj⟩, ⟨pi,pj⟩ 等包含了绝对位置信息的变量。
基于旋转的方案
定义旋转操作:
f(x,i)=Rixi其中 Ri 是正交变换,满足:
RiT=R−i则有:
⟨Rix,Rjy⟩=⟨x,Rj−iy⟩只依赖相对位置,可以看到旋转操作很好满足了我们希望编码函数只包含相对位置关系的要求。
示例:二维旋转
Ri=[cosθisinθi−sinθicosθi],θi=iω问题在于:
Ri=Rj⟺(i−j)ω=2πk因此单个频率的旋转编码具有周期性,在长序列下可能发生位置冲突(collision)。 例如取 ω=1024π,则位置 j=0 和 i=2048 对应相同旋转,模型无法仅通过该二维旋转区分他们的位置。虽然可以通过减小 ω 来增大周期,从而缓解长距离冲突问题,但更小的 ω 会导致 Ri≈Ri+1,即相邻位置之间的旋转差异变小,从而降低局部位置分辨率。
RoPE 的解决方法
因此,RoPE 并不是只使用一个旋转频率,而是在不同二维子空间中使用不同频率进行旋转,也就是说,RoPE 会将一个高维 embedding 拆成多个二维子空间,并分别执行:
RoPE(x,i)=diag(Ri(ωj))j∈[1,…,2d]xi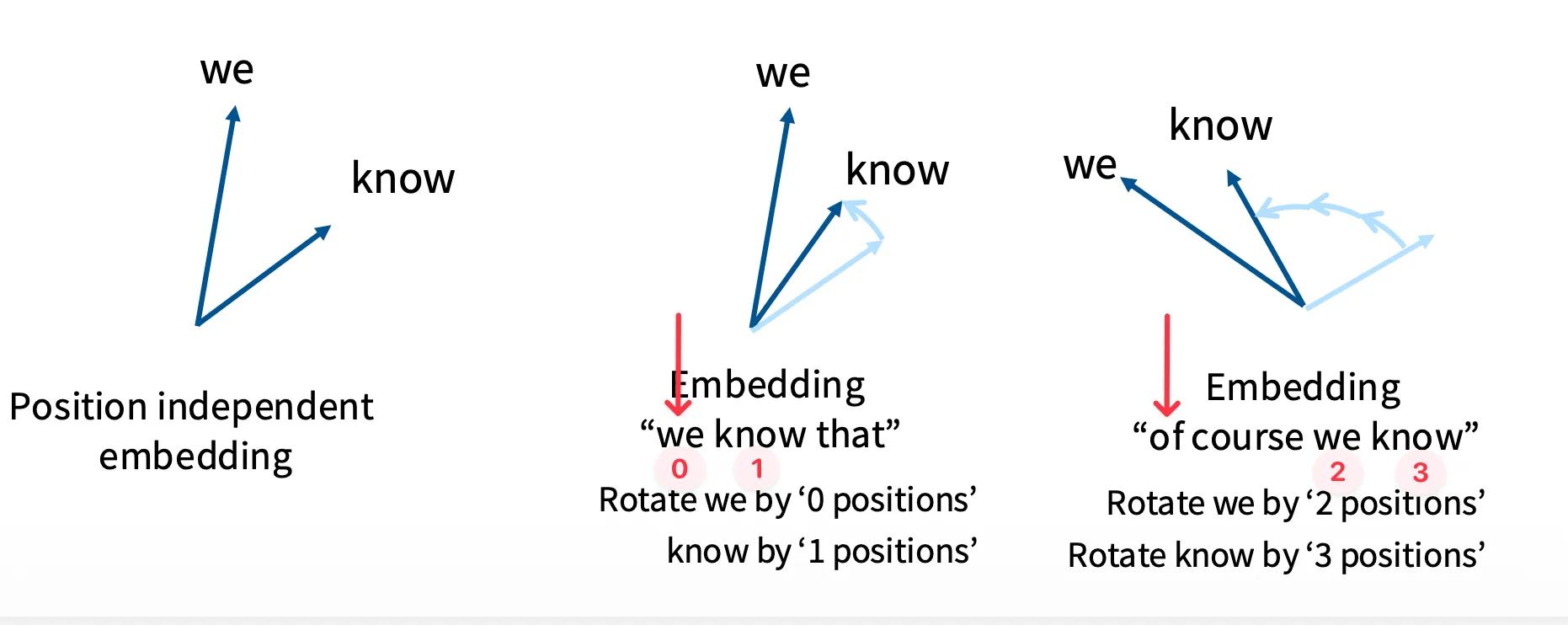
将位置编码为高维“相位向量”,这意味着
- 高频子空间对局部位置变化更敏感
- 低频子空间具有更长的周期,可以表示更远距离关系
数学形式
对 Q 和 K 使用同样的 RoPE 旋转方式:
fQ(xm,m)fK(xm,m)=RΘ,mdWQxm=RΘ,mdWKxm其中:
RΘ,md=cos(mθ1)sin(mθ1)00⋮00−sin(mθ1)cos(mθ1)00⋮0000cos(mθ2)sin(mθ2)⋮00⋯⋯⋯⋯⋱⋯⋯0000⋮cos(mθd/2)sin(mθd/2) θk=10000−2k/d
非线性层避免多个 Attention 退化
如果堆叠两层 attention:
oi=j=1∑nαijV(2)(k=1∑nαjkV(1)xk)=k=1∑n(αjkj=1∑nαij)(V(2)V(1))xk这里 α 分别指代不同层的权重结果,不同层的权重结果是不一致的,这里只是简写。
如果两层 attention 之间没有非线性的话,多层会退化成一层.
因此我们需要在每一层 attention 后,对每个 token 独立应用 MLP:
mi=MLP(outputi)=W2(ReLU(W1⋅outputi+b1)+b2)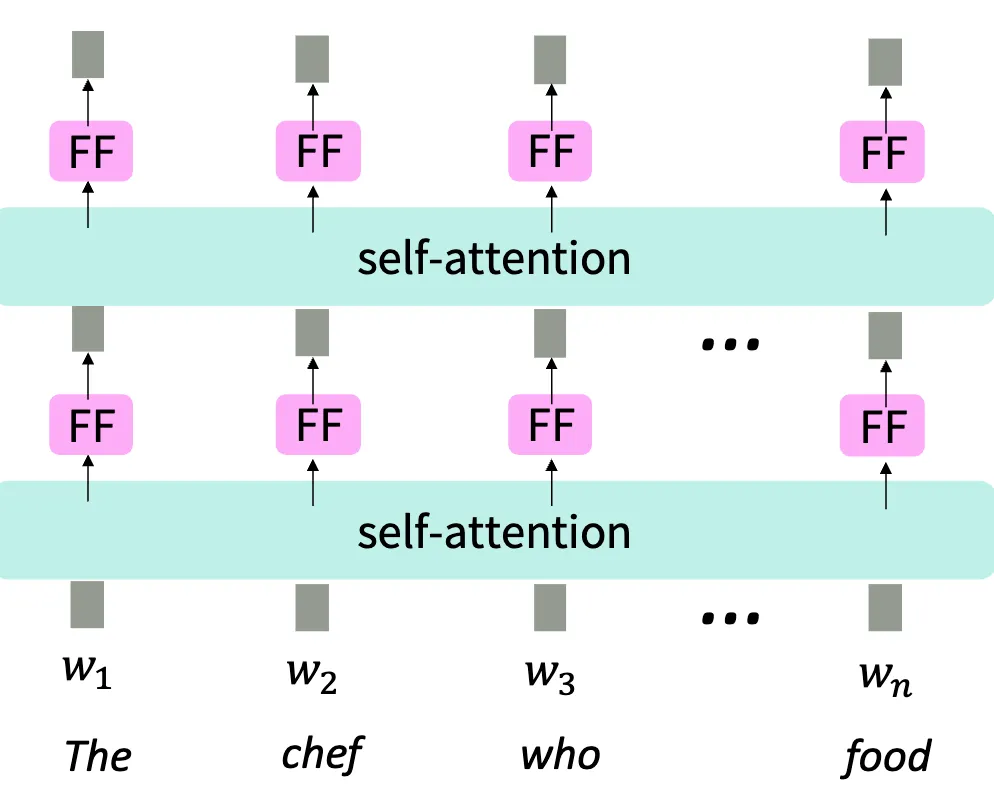
未来信息屏蔽 Masking
在自回归建模中:
wt∼softmax(f(w1:t−1))预测当前位置时,不能看到未来信息。
通过 mask 实现:
αijmasked={αij,−∞,j≤iotherwise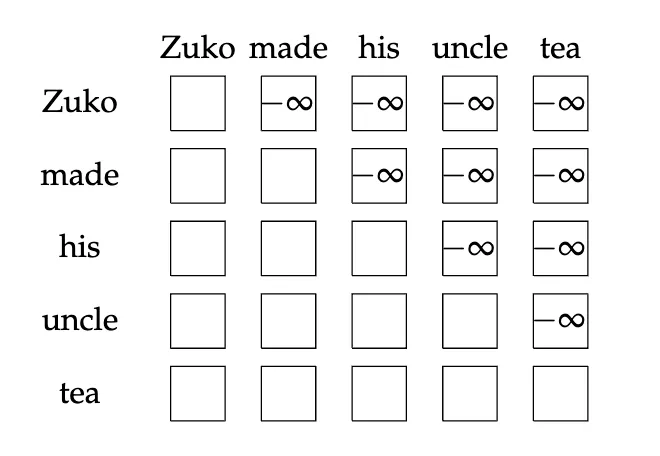
现代大模型推理系统通常不显式构造 mask 矩阵,而是直接读取 Query 向量分别需要和哪些 Key 和 Value 向量进行计算。