Nano vLLM 解读(1):LLMEngine 架构与推理流程解析
4 min
本文介绍了在 Nano-vLLM 系统中,请求是如何被封装、调度,并最终驱动模型推理的。重点关注 LLM Engine 这一层如何连接用户 API 与底层执行系统。
LLM Engine 调用
// example.py
sampling_params = SamplingParams(temperature=0.6, max_tokens=256)
prompts = [
"introduce yourself",
"list all prime numbers within 100",
]
prompts = [
tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
tokenize=False,
add_generation_prompt=True,
)
for prompt in prompts
]
outputs = llm.generate(prompts, sampling_params)LLM Engine 的调用非常简单,只有一行——即调用 generate 函数。generate 接收一个 batch 的请求和对应的采样策略(在后续的系统里可以优化成流式输入),并且最终生成 batch 中每个请求的输出。
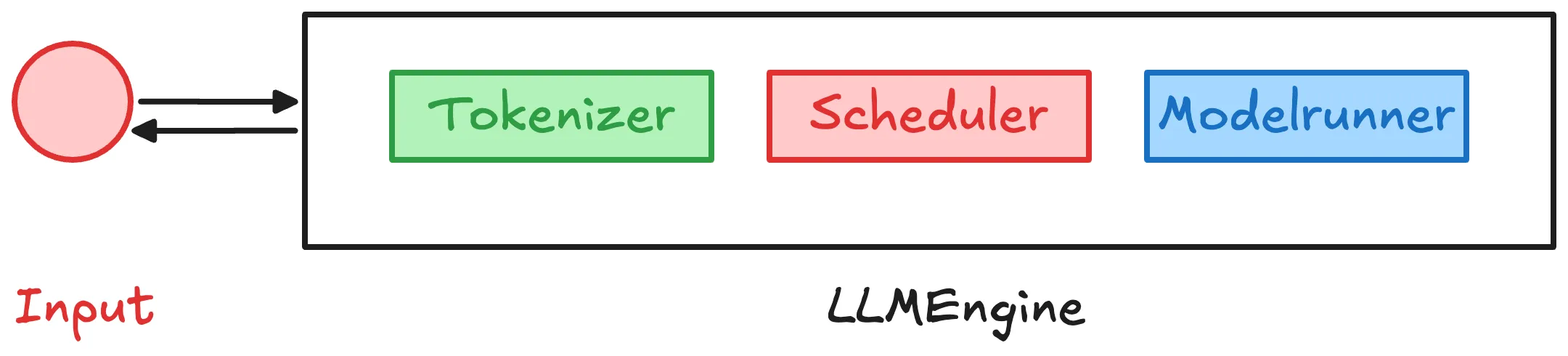
LLM Engine 组成成分
LLMEngine 的核心由两个模块构成:
- Scheduler:负责请求调度与 step 级执行决策(prefill / decode)
- ModelRunner:负责执行具体的模型前向计算
与此同时 LLMEngine 还包括了模型的 tokenizer,用于对请求文本输入进行预处理。
LLM Engine 调用流程
本小节对应 Nano vLLM 的
Engine.generate()API,点击链接跳转。
用一张图来概览 LLM Engine 的调用流程:
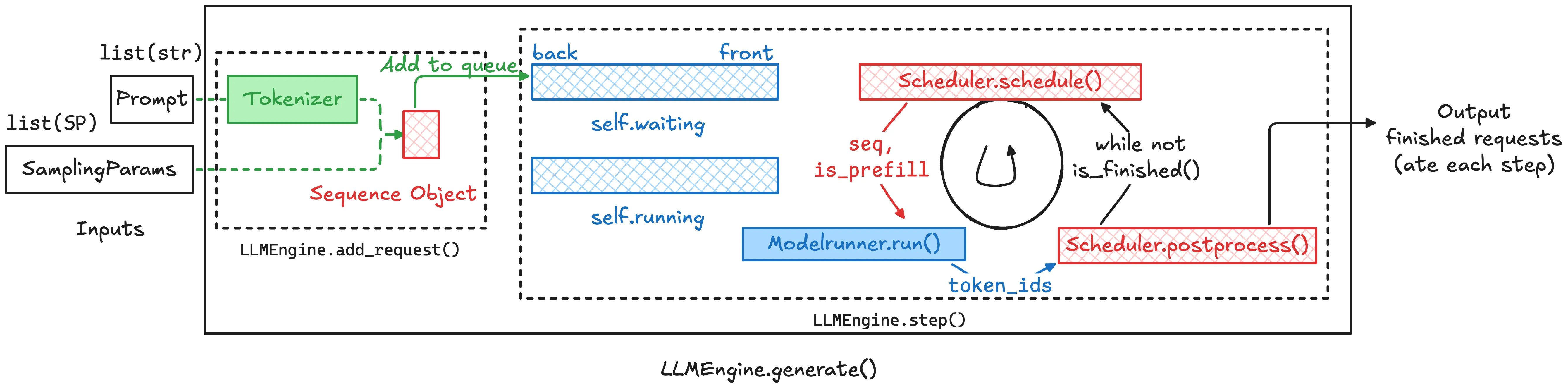
下面代码忽略了实现细节,只是为了表述整体流程。
LLMEngine.generate() 通过 add_request() API 一次性接受多个请求。在一次调用内部,通过反复调用 step() 推进所有请求直到完成(这里不是流式输入,而是一次性提交一批请求):
- 将输入请求
- Tokenize
- 封装成 Sequence 对象(关于 Sequence 对象请参考 Nano vLLM 解读(2):解析 Sequence)
- 调用
scheduler.add()加入 Scheduler waiting queue
- 当 Scheduler 仍有请求没有完成时(通过
scheduler.is_finished()API)- 持续调用
step()。step()每次推进一轮调度与执行,并返回这一轮产生的输出(将在后面解释) - 将获得的输出添加到
outputs中,等待所有请求完成后输出
- 持续调用
class LLMEngine:
def add_request(self, prompt: str | list[int], sampling_params: SamplingParams):
# (1-1): Tokenize
if isinstance(prompt, str):
prompt = self.tokenizer.encode(prompt)
# (1-2): 封装成 Sequence 对象
seq = Sequence(prompt, sampling_params)
# (1-3): 加入 Scheduler waiting queue
self.scheduler.add(seq)
def is_finished(self):
return self.scheduler.is_finished()
def generate(
self,
prompts: list[str] | list[list[int]],
sampling_params: SamplingParams | list[SamplingParams],
use_tqdm: bool = True,
) -> list[str]:
# (1) 将输入请求封装成 Sequence 对象,加入 Scheduler waiting queue
for prompt, sp in zip(prompts, sampling_params):
self.add_request(prompt, sp) # 见上方
outputs = {}
# (2) 循环体判断条件:Scheduler 仍有请求没有完成
while not self.is_finished():
# (2-1):持续调用 self.step() API
output, num_tokens = self.step() # <- 【关键!】将会解释
# (2-2): 将当前轮的输出加入 outputs
for seq_id, token_ids in output:
outputs[seq_id] = token_ids
return outputs在循环体内,我们看到 LLMEngine 调用了一个叫 self.step() 的函数,具体而言:
- 调用
scheduler.schedule()API,决定:哪些 sequence 参与执行?这一轮属于 prefill 还是 decode batch? - 调用
model_runner.run()API,由is_prefillbool 变量控制是执行 Prefill 还是 Decode 的一次前向计算 - 调用
scheduler.postprocess()API,更新序列状态,例如追加生成 token,更新状态,维护 KV Cache 等
class LLMEngine:
def step(self):
# (2-1-1) 由 Scheduler 决定
# 本轮要执行哪些请求
# 本轮要执行 P 还是 D 的一次 iteration?
seqs, is_prefill = self.scheduler.schedule()
# 统计当前批处理的 token 数量,只是为了 benchmark 用
num_tokens = sum(seq.num_scheduled_tokens for seq in seqs) if is_prefill else -len(seqs)
# (2-1-2) 执行这一轮模型的前向计算
token_ids = self.model_runner.call("run", seqs, is_prefill)
# (2-1-3) 更新序列状态,例如追加生成 token,更新状态,维护 KV Cache 等
self.scheduler.postprocess(seqs, token_ids, is_prefill)
outputs = [(seq.seq_id, seq.completion_token_ids) for seq in seqs if seq.is_finished]
return outputs, num_tokens